
随着Sybase被完全整合到SAP下,Sybase原来的支持网站被SAP Support Portal取代。
只有购买了SAP服务的用户才能使用账号登录SAP Support Portal进行介质下载、补丁升级、报Incident等。
目前,原Sybase所有产品(包括:Adaptive Server Enterprise、Sybase IQ、Replication Server、PowerDesigner等)的官方手册仍然可以从https://infocenter.sybase.com/help/index.jsp进行浏览或下载。暂不清楚该网站https://infocenter.sybase.com/help/index.jsp何时会被完全迁移到SAP Support上!
Sybase官方手册英文版有html和pdf两种格式,而中文版手册只有pdf一种格式。为了国内Sybase用户更方便、快捷地搜索Sybase常见产品的官方手册内容,特将中文版Sybase官方手册转为html格式!
Sybase产品官方手册中文版的html格式所有内容的版权归SAP公司所有!本博客站长是Sybase数据库的铁杆粉丝!
如有Sybase数据库技术问题需要咨询,请联系我!
以下官方手册为ASE 15.7 ESD#2中文版:
- 新增功能公告 适用于 Windows、Linux 和 UNIX 的 Open Server 15.7 和 SDK 15.7
- 新增功能摘要
- 新增功能指南
- ASE 15.7 发行公告
- 配置指南(windows)
- 安装指南(windows)
- 参考手册:构件块
- 参考手册:命令
- 参考手册:过程
- 参考手册:表
- Transact-SQL® 用户指南
- 系统管理指南,卷 1
- 系统管理指南,卷 2
- 性能和调优系列:基础知识
- 性能和调优系列:锁定和并发控制
- 性能和调优系列:监控表
- 性能和调优系列:物理数据库调优
- 性能和调优系列:查询处理和抽象计划
- 性能和调优系列:使用 sp_sysmon 监控 Adaptive Server
- 性能和调优系列:利用统计分析改进性能
- 程序员参考 jConnect for JDBC 7.0.7
- Adaptive Server Enterprise 中的 Java
- 组件集成服务用户指南
- Ribo 用户指南
- 内存数据库用户指南
- Sybase Control Center for Adaptive Server® Enterprise
- 安全性管理指南
- 实用程序指南
create table
说明 • 创建新表和 (可选)完整性约束。
• 定义计算列。
• 定义表、行和分区的压缩级别。
• 定义加密列及其解密缺省值。
• 定义表的分区属性。用于创建表分区的语法在下面单独列出。请参 见分区的语法。
语法 create table [[database.[owner].]table_name (column_name datatype
[default {constant_expression | user | null}] [{identity | null | not null}]
[ in row [(length)] | off row ] [[constraint constraint_name]
{{unique | primary key}
[clustered | nonclustered] [asc | desc] [with {fillfactor = pct,
max_rows_per_page = num_rows,} reservepagegap = num_pages] dml_logging = {full | minimal}
[deferred_allocation | immediate_allocation]) [on segment_name]
| references [[database.]owner.]ref_table [(ref_column)]
[match full]
| check (search_condition)}]} [[encrypt [with [database.[owner].]key_name]
[decrypt_default constant_expression | null]]
[not compressed]
[compressed = {compression_level | not compressed} [[constraint [[database.[owner].]key_name]
{unique | primary key} [clustered | nonclustered] (column_name [asc | desc]
[{, column_name [asc | desc]}...]) [with {fillfactor = pct
max_rows_per_page = num_rows, reservepagegap = num_pages}]
[on segment_name]
| foreign key (column_name [{,column_name}...]) references [[database.]owner.]ref_table [(ref_column [{, ref_column}...])]
[match full]
| check (search_condition) ...}
[{, {next_column | next_constraint}}...]) [lock {datarows | datapages | allpages}] [with {max_rows_per_page = num_rows,
exp_row_size = num_bytes, reservepagegap = num_pages, identity_gap = value
transfer table [on | off] dml_logging = {full | minimal}
compression = {none | page | row}}] lob_compression = off | compression_level
[on segment_name] [partition_clause]
[[external table] at pathname] [for load] compression_clause::=
with compression = {none | page | row}
将此语法用于分区:
partition_clause::=
partition by range (column_name[, column_name]...) ([partition_name] values <= ({constant | MAX}
[, {constant | MAX}] ...)
[compression_clause] [on segment_name] [, [partition_name] values <= ({constant | MAX}
[, {constant | MAX}] ...)
[compression_clause] [on segment_name]]...)
| partition by hash (column_name[, column_name]...)
{ (partition_name
[compression_clause] [on segment_name] [, partition_name
[compression_clause] [on segment_name]]...)
| number_of_partitions
[on (segment_name[, segment_name] ...)]}
| partition by list (column_name)
([partition_name] values (constant[, constant] ...) [compression_clause] [on segment_name]
[, [partition_name] values (constant[, constant] ...) [compression_clause] [on segment_name]]...)
| partition by roundrobin
{ (partition_name [on segment_name] [, partition_name
[compression_clause] [on segment_name]]...)
| number_of_partitions
[on (segment_name[, segment_name]...)]}
将此语法用于计算列
create table [[database.[owner].] table_name
(column_name {compute | as}
computed_column_expression
[[materialized] [not compressed]] | [not materialized]}
使用此语法创建虚拟散列表
create table [database.[owner].]table_name
. . .
| {unique | primary key} using clustered
(column_name [asc | desc] [{, column_name [asc | desc]}...])= (hash_factor [{, hash_factor}...])
参数 table_name
是新表的显式名称。如果该表位于另一数据库中,请指定数据库名; 如果数据库中有多个具有该名称的表,请指定所有者的名称。 owner 的缺省值是当前用户,而 database 的缺省值是当前数据库。
不能对表名使用变量。表名在数据库内必须唯一,且对所有者也必须 唯一。如果设置了 set quoted_identifier on ,就可以对表名使用分隔标 识符。另外,它必须符合标识符的规则。有关有效表名的详细信息, 请参见 《参考手册:构件块》第 4 章 “表达式、标识符和通配符” 中第 349 页的 “标识符”。
通过在表名前加井号 ( # ) 或 “tempdb..”可以创建临时表。请参见
《参考手册:构件块》第 4 章 “表达式、标识符和通配符”中第 352
页的 “以 # 开头的表 (临时表)”。
可以在另一数据库中创建表,只要您被列在 sysusers 表中并具有对该 数据库的 create table 权限。例如,可以使用以下两种方法之一在数据 库 otherdb 中创建一个名为 newtable 的表:
create table otherdb..newtable
create table otherdb.yourname.newtable
column_name
是表中列的名称。它在表中必须是唯一的。如果设置了 set quoted_identifier on ,就可以为列使用分隔标识符。另外,它必须符合 标识符的规则。有关有效列名的详细信息,请参见 《参考手册:构 件块》第 4 章 “表达式、标识符和通配符”。
datatype
是列的数据类型。可接受系统数据类型或用户定义的数据类型。某些 数据类型需要在括号中使用长度 n:
datatype (n)
其它类型要求使用精度 p 和标度 s:
datatype (p,s)
有关详细信息,请参见 《参考手册:构件块》第 1 章 “系统数据类 型和用户定义的数据类型”。
如果数据库中启用了 Java, datatype 可以是安装在数据库中的 Java 类 的名称,这个类可以是系统类或用户定义的类。有关详细信息,请参 见 《Adaptive Server Enterprise 中的 Java》。
default
指定列的缺省值。如果您指定了缺省值,而用户在插入数据时没有为 列提供值, Adaptive Server 就会插入缺省值。缺省值可以是常量表达 式、内置值 (插入执行插入操作的用户的名称)或者是 null (插入空 值)。Adaptive Server 以 tabname_colname_objid 为格式生成缺省名称, 其中 tabname 是表名的前 10 个字符, colname 是列名的前 5 个字符, 而 objid 是缺省对象 ID 号。使用 IDENTITY 属性为列声明的缺省值不 会影响列值。
可以在不引用数据库对象的 create table 语句的 default 部分引用全局变 量。但不能在 create table 的 check 部分使用全局变量。
constant_expression 是用作列的缺省值的常量表达式。它不能包含全局变量、任何列的名 称或其它数据库对象,但可以包括不引用数据库对象的内置函数。缺 省值必须与该列的数据类型兼容,否则在试图插入缺省值时, Adaptive Server 会生成数据类型转换错误。
user | null
指定如果用户不提供值, Adaptive Server 应插入用户名或 NULL 值作 为缺省值。对于 user,列的数据类型必须是 char (30) 或 varchar (30)。 对于 null,列必须允许空值。
identity
表示该列具有 IDENTITY 属性。数据库中的每个表都可以具有一个以 下数据类型的 IDENTITY 列:
• 精确 numeric 类型,标度为 0,或
• 任意整数数据类型,包括有符号或无符号 bigint、 int、 smallint 或
tinyint。
IDENTITY 列不能更新,也不允许有空值。
IDENTITY 列用于存储由 Adaptive Server 自动生成的序列号,如发票 编号或职员编号。 IDENTITY 列的值唯一地标识表的每一行。
null | not null
指定在无缺省值的情况下,Adaptive Server 在数据插入过程中的行为。
null 指定如果用户没有提供值,则 Adaptive Server 分配一个空值。
not null 指定如果没有缺省值,则用户必须提供一个非空值。
Bit 类型列的属性必须始终为 not null。
如果不指定 null 或 not null,缺省情况下 Adaptive Server 将使用 not null。不过,为了使此缺省值与 SQL 标准兼容,可以使用 sp_dboption 对它进行切换。
in row
指示 Adaptive Server 凡是在数据页中有足够空间的情况下都将 LOB 列中的数据存储为行内。 LOB 列的数据要么完全存储为行内,要么 完全存储为行外。
length
(可选)指定 LOB 列数据可以存储为行内的最大大小。任何大于此 值的数据都存储为行外,而等于或小于 length 的数据都存储为行内
(只要页上有足够的空间)。
如果您不指定 length, Adaptive Server 会将数据库范围设置用于行内 长度。
off row
(可选)提供在行外存储 LOB 列的缺省行为。 Adaptive Server 会对您 的新表采用此行为,除非您指定了 in row。如果您不指定 off row 子 句,而且设置了数据库范围的行内长度,create table 就会将 LOB 列创 建为行内 LOB 列。
off row | in row
指定 Java-SQL 列是和行分开存储 (off row) 还是存储在行中直接分配的 存储区 (in row)。
缺省值是 off row。请参见 《Adaptive Server Enterprise 中的 Java》。
size_in_bytes 指定行内列的最大大小。根据数据库服务器的页大小和其它变量,存 储在行内的对象最多可占据约 16K 字节的空间。缺省值为 255 个字节。
constraint constraint_name
引入完整性约束的名称。
constraint_name 是约束的名称。它必须符合标识符的规则,并且在数 据库中是唯一的。如果不指定引用或检查约束的名称, Adaptive Server 会生成 tabname_colname_objectid 格式的名称,其中:
• tabname – 是表名的前 10 个字符
• colname – 是列名的前 5 个字符
• objectid – 是约束的对象 ID 号
如果没有为唯一约束或主键约束指定名称, Adaptive Server 会生成格 式为 tabname_colname_tabindid 的名称,其中 tabindid 是表 ID 和索引 ID 的字符串并置。
unique
约束所指定列中的值,使得任两行都不能具有相同的值。此约束将创建 一个唯一索引,该索引仅在使用 alter table 删除了约束后才能被删除。
primary key 约束所指定列中的值,使得任两行都不能具有相同的值,因此值不能 为 NULL 。此约束将创建一个唯一索引,该索引仅在使用 alter table 删 除了约束后才能被删除。
clustered | nonclustered
指定由 unique 或 primary key 约束创建的索引是聚簇索引还是非聚簇索 引。 clustered 是主键约束的缺省值;nonclustered 是唯一约束的缺省值。 每个表只能有一个聚簇索引。有关详细信息,请参见 create index。
asc | desc 指定为约束创建的索引以每列的升序还是降序创建。缺省设置是按升 序排列。
指定 Adaptive Server 对现有数据创建新索引时使每一页达到的填满程 度。 fillfactor 百分比仅在创建索引时使用。随着数据的变化,页不会 维持在某个特定的填充程度。
fillfactor 的缺省值是 0 ,这个值在您未在 create index 语句中包括 with fillfactor 时使用 (除非使用 sp_configure 更改了该值)。指定 fillfactor 时,请使用介于 1 和 100 之间的值。
fillfactor 值为 0 可创建具有完全填充页的聚簇索引及具有完全填充叶页 的非聚簇索引。它在聚簇索引和非聚簇索引的索引 B 树内都保留适量 的空间。通常不需要更改 fillfactor。
如果将 fillfactor 设置为 100,Adaptive Server 在创建聚簇索引和非聚簇 索引时,会使每页的占满度达到 100%。将 fillfactor 的值设置为 100 仅 对只读表 (永不向其中添加数据的表)才有意义。
如果 fillfactor 的值小于 100(0 除外,0 是特殊情况),Adaptive Server 在 创建新索引时不会填满每页。创建表的索引时,如果表最终将包含大 量数据,那么将 fillfactor 的值设置为 10 可能是一种明智的选择,但较小 的 fillfactor 值会导致每个索引 (或索引和数据)占用较多的存储空间。
如果启用了 CIS,则不能对远程服务器使用 fillfactor。
![]()
警告! 使用 fillfactor 创建聚簇索引会影响数据占用的存储空间,因为创 建聚簇索引时 Adaptive Server 会重新分配数据。
![]()
decrypt_default 能让 sso 指定向没有加密列解密权限的用户返回的值。解 密缺省值将被替换为通过 select 语句检索到的 text、image 或 unitext 列。
max_rows_per_page 限制数据页和索引的叶级页上的行数。与 fillfactor 不同, max_rows_per_page 的值在插入或删除数据时保持不变。
如果不指定 max_rows_per_page 的值, Adaptive Server 将在创建表时 使用值 0。表和聚簇索引的值在 0 到 256 之间。非聚簇索引的每页最 大行数取决于索引键的大小;如果指定的值过高, Adaptive Server 会 返回错误消息。
max_rows_per_page 值为 0 可创建具有完全填充页的聚簇索引及具有 完全填充叶页的非聚簇索引。它在聚簇索引和非聚簇索引的索引 B 树 中都保留适量空间。
对 max_rows_per_page 使用低值可减少经常访问的数据的锁争用。然 而,使用低值也会导致 Adaptive Server 创建具有不完全填充页的索 引,使用更多存储空间,并可能导致更多的页面拆分。
如果启用了 CIS 并创建了代理表,则会忽略 max_rows_per_page。代 理表不包含任何数据。如果用 max_rows_per_page 创建了一个表,然 后创建了代理表引用此表,那么当您通过代理表进行 insert 或 delete 时,将应用 max_rows_per_page 限制。
reservepagegap = num_pages
指定填充页与空白页的比率,扩充 I/O 分配操作过程中要保留该比率 的空白页。对于每个指定的 num_pages,都会预留一个空白页供表将 来扩展之用。有效值为 0 到 255。缺省值为 0。
dml_logging = {full | minimal}
确定 insert、update 和 delete 操作以及某些形式的批量插入的日志记录 量。以下值之一:
• full – Adaptive Server 记录所有事务
• minimal –Adaptive Sever 不记录行或页更改
deferred_allocation
将表或索引的创建延迟到需要表时。在第一次 insert 时创建延迟表。
immediate_allocation
启用 sp_dboption 'deferred table allocation' 后显式创建表。
on segment_name
当与 constraint 选项一起使用时,指定要在已命名的段上创建索引。 在使用 on segment_name 选项之前,必须使用 disk init 初始化设备,并 使用 sp_addsegment 将段添加到数据库。要获得数据库中可用段名的 列表,请咨询系统管理员或使用 sp_helpsegment。
如果指定 clustered 并使用 on segment_name 选项,则整个表都将迁移 到您指定的段,因为索引的叶级包含实际的数据页。
references 为参照完整性约束指定列列表。只能为一个列约束指定一个列值。通 过将此约束包括到引用其它表的表中,插入到引用 表中的任何数据 都必须已经存在于被引用 表中。
若要使用此约束,必须对被引用表拥有 references 权限。被引用表中 的指定列必须由唯一索引 (由 unique 约束或 create index 语句创建) 约束。如果未指定任何列,则在被引用表的适当列中必须有一个 primary key 约束。而且,引用表列的数据类型必须和被引用表列的数 据类型匹配。
ref_table
是包含被引用列的表的名称。您可以引用其它数据库中的表。约束可 引用最多 192 个用户表和内部生成的工作表。
ref_column
是被引用表中的列的名称。
match full
指定如果引用行的引用列中的所有值均为:
• 空值 – 参照完整性条件为真。
• 非空值 – 如果被引用行中每个对应的列在被引用表中都相等, 则参照完整性条件为真。
如果不属于上述任何一种情况,则参照完整性条件在以下条件成立时 为假:
• 所有的值都是非空值且不相等,或者
• 引用行的引用列中的某些值是非空值,而其它值为空。
check ( search_condition)
指定列值的 check 约束以及 Adaptive Server 对表中的所有行都实施的 search_condition 约束。可以指定 check 约束作为表或列约束;create table 允许一个列定义中有多个 check 约束。
虽然可以在 create table 语句的 default 部分引用全局变量,但是不能在
check 部分使用它们。
这些约束可以包括:
• 用 in 引入的一系列常量表达式
• 由 like 引入的一组条件,可以包含通配符 列和表检查约束可引用表中的任何列。
表达式可包括算术运算符和函数。 search_condition 不能包含子查询、 集合函数、主变量或参数。
encrypt [with key_name] 创建加密列。如果密钥在另一数据库中,则指定数据库名称。如果 key_name 对于数据库不唯一,则指定所有者的名称。 owner 的缺省值 是当前用户,而 database 的缺省值是当前数据库。
表的创建者必须对密钥具有 select 权限。如果不提供 key_name,
Adaptive Server 将在数据库中查找缺省密钥。
keyname 标识使用 create encryption key 创建的密钥。表创建者必须对 keyname 具有 select 权限。如果未提供 keyname,Adaptive Server 将查 找通过在 create encryption key 或 alter encryption key 中使用 as default 子 句创建的缺省密钥。
有关支持的数据类型的列表,请参见 《加密列用户指南》中的 “加 密数据”。
decrypt_default constant_expression 指定此列为没有解密权限的用户返回缺省值, constant_expression 是 Adaptive Server 对 select 语句返回的常量值,而不是解密值。该值只 能在可空列中为 NULL。如果解密缺省值无法转换为列的数据类型, 则仅当 Adaptive Server 执行查询时,它才会捕捉转换错误。
compression = compression_level | not compressed
foreign key
指定列出的列是该表中的外键,这些外键的目标键为随后的 references 子句中列出的列。foreign key 语法只允许用于表级约束,不 允许用于列级约束。
next_column | next_constraint 表示可以使用与列定义或表约束定义相同的语法包括附加列定义或表 约束 (以逗号分隔)。
lock datarows | datapages | allpages 指定要对表使用的锁定方案。缺省值是对配置参数 lock scheme 的全 服务器范围的设置。
exp_row_size = num_bytes
指定所需行宽;仅适用于 datarows 和 datapages 锁定方案,且仅适用 于具有可变长度行的表。有效值可以是 0、 1 以及介于表的最小和最 大行长度之间的任何值。缺省值为 0,表示应用服务器范围的设置。
identity_gap value
指定表的标识间隔。该值只替换此表的系统标识间隔设置。
value 是标识间隔量。有关设置标识间隔的详细信息,请参见 第 228 页的 “ IDENTITY 列 ” 。
transfer table [on | off]
将表标记为进行增量传输。此参数的缺省值为 off。 dml_logging
确定 insert、update 和 delete 操作以及某些形式的批量插入的日志记录
量。以下值之一:
• full – Adaptive Server 记录所有事务
• minimal – Adaptive Sever 不记录行或页更改
compression 指示在表级或分区级设置压缩的级别。指定分区的压缩级别会覆盖表 的压缩级别。 Adaptive Server 仅在配置了压缩的分区中压缩各个列。
• none - 不压缩该表或分区中的数据。对于分区, none 指示该分区 中的数据保持不压缩,即使将表压缩改为 row 或 page 压缩也是如 此。
• row – 压缩单个行中的一个或多个数据项。只有在压缩形式比非 压缩形式更节省空间时, Adaptive Server 才会用 row 压缩形式存 储数据。在分区级或表级设置 row 压缩。
• page – 当页面已满时,则会使用页级压缩来压缩现有的采用行 压缩形式的数据行,从而创建页级字典、索引和字符编码条目。 在分区级或表级设置 page 压缩。
Adaptive Server 只有已经在行级压缩数据后才会在页级压缩数据, 因此,将压缩级别设置为 page 意味同时进行 page 和 row 压缩。
lob_compression = off | compression_level
决定表的压缩级别。如果您选择 off,表将不具有 LOB 压缩。
compression_level
表压缩级别。压缩级别有:
• 0 – 不压缩行。
• 1 到 9 - Adaptive Server 使用 ZLib 压缩。通常,压缩级别数字越 大, Adaptive Server 压缩 LOB 数据的程度就更大,压缩和非压缩 数据之间的比率就越大 (也就是说,压缩数据与非压缩数据大小 相比,节省的空间量就越大 (以字节为单位))。
但是,压缩量取决于 LOB 内容,压缩级别越高,进程的 CPU 占 用率就越高。也就是说,级别 9 提供的压缩率最高,但 CPU 使用 率也最高。
• 100 – Adaptive Server 使用 FastLZ 压缩。这是 CPU 使用率最低的 压缩率;通常用于较少的数据量。
• 101 – Adaptive Server 使用 FastLZ 压缩。与值为 100 时相比,值 为 101 时的 CPU 占用率略高,但压缩率也略高。
压缩算法忽略不使用 LOB 数据的行。
on segment_name
指定要在其上放置表的段的名称。使用 on segment_name 时,必须已 经用 create database 或 alter database 将逻辑设备指派给了数据库,且 必须已经用 sp_addsegment 在数据库中创建了段。要获得数据库中可 用段名的列表,请咨询系统管理员或使用 sp_helpsegment。
external table
指定对象是远程表还是视图。缺省值为 external table,因此可指定也 可不指定该选项。
for load
创建仅可用于 bcp in 和 alter table unpartition 操作的表。可对使用 for load
创建的表使用 row_count()。
partition by range
指定要根据一个或多个分区列中指定的范围值对记录分区。
column_name
在 partition_clause 中使用时,指定一个分区键列。
partition_name 指定要在其上存储表记录的新分区的名称。分区名称在表或索引上的 分区组内必须唯一。如果启用 set quoted_identifier,则分区名称可以是 分隔标识符。否则,分区名称必须是有效的标识符。
如果省略 partition_name, Adaptive Server 将创建一个格式为 table_name_patition_id 的名称。Adaptive Server 将截断超过允许的最大 长度的分区名称。
on segment_name
在 partition_clause 中使用时,指定将在其上放置分区的段。在使用 on segment_name 选项之前,必须使用 disk init 初始化设备,并使用 sp_addsegment 系统过程将段添加到数据库。要获得数据库中可用段 名的列表,请咨询系统管理员或使用 sp_helpsegment。
values <= constant | MAX
指定命名分区的上限值 (包括边界值)。为最高分区上限指定常量值 将在表上施加隐式完整性约束。关键字 MAX 指定给定数据类型的最 大值。
partition by hash 指定要按系统提供的散列函数对记录分区。该函数计算分区键的散列 值,这些分区键指定将记录分配到的分区。
partition by list 指定要按命名列中指定的实际值对记录分区。只有一个列能够对列表 分区表分区。最多可以为每个分区指定 250 个不同列表值。
partition by round-robin 指定要按顺序方式对记录分区。循环分区表没有分区键。用户和优化 程序都不知道特定记录的分区。
at pathname
指定远程对象的位置。使用 at pathname 子句会导致创建一个代理表。
pathname 的格式为 server_name.dbname.owner.object;aux1.aux2,其中:
• server_name (必需) - 是包含远程对象的服务器的名称。
• dbname (可选)是包含此对象的远程服务器所管理的数据库的 名称。
• owner (可选)是拥有远程对象的远程服务器用户的名称。
• object (必需)是远程表或视图的名称。
• aux1.aux2 (可选)– 是在执行 create table 或 create index 命令期 间传递给远程服务器的字符串。该字符串仅在服务器是 db2 类时 使用。 aux1 是在其中放置表的 DB2 数据库, aux2 是在其中放置 表的 DB2 表空间。
{compute | as}
可交替使用的保留关键字,用于表明列是计算列。
computed_column_expression
是任意有效的 T-SQL 表达式,该表达式不包含来自其它表、局部变 量、集合函数或子查询的列。它可以是由一个或多个运算符连接起来 的列名、常量、函数、全局变量、 case 表达式或它们的组合。除虚拟 计算列引用实现计算列以外,不能在计算列之间进行交叉应用。
materialized | not materialized 指定是否实现计算列并将其物理地存储在表中。如果没有指定关键 字,则计算列缺省为 not materialized,因此不物理地存储在表中。
using clustered
指示您要创建虚拟散列表。列列表将被视为此表的键列。
column_name [asc | desc]
由于行基于其散列函数放置,因此不能将 [asc | desc] 用于散列区域。 如果提供虚拟散列表的键列顺序,该顺序将只用于溢出聚簇区域。
hash_factor 用于虚拟散列表的散列函数所必需的参数。对于散列函数,每个键列 都需要一个散列因子。这些因子与键值一起使用,以便为特定行生成 散列值。
with max num_hash_values key
可以使用的最大散列值数。定义此散列函数输出的上限。
示例 示例 1 使用 @@spid 全局变量与缺省参数创建 foo 表:
create table foo (
a int
, b int default @@spid
)
示例 2 创建 titles 表:
create table titles (
|
, |
title |
varchar (80) |
not null |
|
, |
type |
char (12) |
not null |
|
, |
pub_id |
char (4) |
null |
|
, |
price |
money |
null |
|
, |
advance |
money |
null |
|
, |
total_sales |
int |
null |
|
, |
notes |
varchar (200) |
null |
|
, |
pubdate |
datetime |
not null |
|
, |
contract |
bit |
not null |
|
, |
title |
varchar (80) |
not null |
|
, |
type |
char (12) |
not null |
|
, |
pub_id |
char (4) |
null |
|
, |
price |
money |
null |
|
, |
advance |
money |
null |
|
, |
total_sales |
int |
null |
|
, |
notes |
varchar (200) |
null |
|
, |
pubdate |
datetime |
not null |
|
, |
contract |
bit |
not null |
title_id tid not null
)
示例 3 使用 for load 创建表 mytable:
create table mytable ( col1 int
, col2 int
, col3 (char 50)
)
partitioned by roundrobin 3 for load
在取消分区之前,新表不可用于任何用户活动。
1 使用 bcp in 将数据装载到 mytable。 2 取消对 mytable 的分区。 现在,该表可用于任何用户活动。
示例 4 创建 compute 表。因为表名和列名 (max 和 min)是保留字,所以 用双引号引起来。因为 total score 列名中包含嵌入的空格,所以用双引 号引起来。创建此表之前,必须先执行 set quoted_identifier on。
create table "compute" ( "max" int
, "min" int
, "total score" int
)
示例 5 在一步中创建具有唯一约束的 sales 表和聚簇索引。(在 pubs2 数 据库安装脚本中,有单独的 create table 和 create ind ex 语句):
create table sales (
stor_id char (4) not null
, ord_num varchar (20) not null
, date datetime not null
, unique clustered (stor_id, ord_num)
)
示例 6 创建具有两个参照完整性约束和一个缺省值的 salesdetail 表。有一 个名为 salesdet_constr 的表级参照完整性约束和 title_id 列上的一个无指定 名称的列级参照完整性约束。两个约束都指定被引用表 (titles 和 sales) 中具有唯一索引的列。带有 qty 列的 default 子句指定 0 作为其缺省值。
create table salesdetail (
stor_id char (4) not null
, ord_num varchar (20) not null
, title_id tid not null
references titles (title_id)
, qty smallint default 0 not null
, discount float not null,
constraint salesdet_constr foreign key (stor_id, ord_num)
references sales (stor_id, ord_num)
)
示例 7 创建在 pub_id 列上具有检查约束的 publishers 表。此列级约束可用 于代替 pubs2 数据库中的 pub_idrule。
create rule pub_idrule
as @pub_id in ("1389", "0736", "0877", "1622", "1756")
or @pub_id like "99[0-9][0-9]"
create table publishers ( pub_id char (4) not null
check (pub_id in ("1389", "0736", "0877", "1622",
"1756")
or pub_id like "99[0-9][0-9]")
, pub_name varchar (40) null
, city varchar (20) null
, state char (2) null
)
示例 8 指定 ord_num 列作为 sales_daily 表的 IDENTITY 列。首次向表中 插入行时,Adaptive Server 为 IDENTITY 列指派值 1。以后每次插入时, 此列的值都会增加 1。
create table sales_daily (
|
stor_id |
char (4) |
not null |
|
, ord_num |
numeric (10,0) |
identity |
, ord_amt money null
)
示例 9 为 new_titles 表指定数据页锁定方案和所需行宽 200:
|
title_id |
tid |
||
|
, |
title |
varchar (80) |
not null |
|
, |
type |
char (12) |
|
|
, |
pub_id |
char (4) |
null |
|
, |
price |
money |
null |
|
, |
advance |
money |
null |
|
, |
total_sales |
int |
null |
|
, |
notes |
varchar (200) |
null |
|
, |
pubdate |
datetime |
|
|
, |
contract |
bit |
|
title_id |
tid |
||
|
, |
title |
varchar (80) |
not null |
|
, |
type |
char (12) |
|
|
, |
pub_id |
char (4) |
null |
|
, |
price |
money |
null |
|
, |
advance |
money |
null |
|
, |
total_sales |
int |
null |
|
, |
notes |
varchar (200) |
null |
|
, |
pubdate |
datetime |
|
|
, |
contract |
bit |
create table new_titles (
)
lock datapages
with exp_row_size = 200
示例 10 指定 datarows 锁定方案并将 reservepagegap 值设置为 16,以使扩 充 I/O 操作为每 15 个填充页留出 1 个空白页:
|
pub_id |
char (4) |
not null |
|
|
, |
pub_name |
varchar (40) |
null |
|
, |
city |
varchar (20) |
null |
|
, |
state |
char (2) |
null |
|
pub_id |
char (4) |
not null |
|
|
, |
pub_name |
varchar (40) |
null |
|
, |
city |
varchar (20) |
null |
|
, |
state |
char (2) |
null |
create table new_publishers (
)
lock datarows
with reservepagegap = 16
示例 11 创建名为 big_sales 并且记录日志最少的表:
create table big_sales (
storid char(4) not null
, ord_num varchar(20) not null
, order_date datetime not null
)
with dml_logging = minimal
示例 12 创建一个名为 im_not_here_yet 的延迟表:
create table im_not_here_yet ( col_1 int,
col_2 varchar(20)
)
with deferred_allocation
示例 13 创建一个名为 mytable 的表,该表使用锁定方案数据行并允许增 量传输:
create table mytable ( f1 int
, f2 bigint not null
, f3 varchar (255) null
)
lock datarows
with transfer table on
示例 14 创建一个名为 genre、采用行级压缩的表:
create table genre (
|
, |
novel |
varchar(50) |
not |
null |
|
, |
psych |
varchar(50) |
not |
null |
|
, |
history |
varchar(50) |
not |
null |
|
, |
art |
varchar(50) |
not |
null |
|
, |
science |
varchar(50) |
not |
null |
|
, |
children |
varchar(50) |
not |
null |
|
, |
cooking |
varchar(50) |
not |
null |
|
, |
gardening |
varchar(50) |
not |
null |
|
, |
poetry |
varchar(50) |
not |
null |
|
, |
novel |
varchar(50) |
not |
null |
|
, |
psych |
varchar(50) |
not |
null |
|
, |
history |
varchar(50) |
not |
null |
|
, |
art |
varchar(50) |
not |
null |
|
, |
science |
varchar(50) |
not |
null |
|
, |
children |
varchar(50) |
not |
null |
|
, |
cooking |
varchar(50) |
not |
null |
|
, |
gardening |
varchar(50) |
not |
null |
|
, |
poetry |
varchar(50) |
not |
null |
mystery varchar(50) not null
)
with compression = row
示例 15 在段 seg1、 seg2 和 seg3 上创建一个名为 sales 的表,且 seg1 上 具有压缩:
create table sales (
store_id int not null
, order_num int not null
, date datetime not null
)
partition by range (date)
( Y2008 values <= ('12/31/2008')
with compression = page on seg1,
Y2009 values <= ('12/31/2009') on seg2, Y2010 values <= ('12/31/2010') on seg3)
示例 16 创建 email 表,该表使用 LOB 压缩级别 5:
create table email ( user_name char (10)
, mailtxt text
, photo image
, reply_mails text) with lob_compression = 5
示例 17 创建一个唯一聚簇索引所支持的约束;索引顺序对 stor_id 为升 序,对 ord_num 为降序:
|
stor_id |
char (4) |
not |
null |
|
|
, |
ord_num |
varchar (20) |
not |
null |
|
, |
date |
datetime |
not |
null |
|
stor_id |
char (4) |
not |
null |
|
|
, |
ord_num |
varchar (20) |
not |
null |
|
, |
date |
datetime |
not |
null |
create table sales_south (
, unique clustered (stor_id asc, ord_num desc)
)
示例 18 在远程服务器 SERVER_A 上创建一个名为 t1 的表,并创建一个 映射到该远程表的名为 t1 的代理表:
create table t1 (
a int
, b char (10)
)
at "SERVER_A.db1.joe.t1"
示例 19 创建一个名为 employees 的表。 name 的类型为 varchar, home_addr 是类型为 Address 的 Java-SQL 列,而 mailing_addr 是类型为 Address2Line 的 Java-SQL 列。Address 和 Address2Line 都是安装在数据库 中的 Java 类:
create table employees (
name varchar (30)
, home_addr Address
, mailing_addr Address2Line
)
示例 20 创建一个带 identity 列的名为 mytable 的表。标识间隔设置为 10, 表示将在内存中以十个 ID 号的块为单位分配 ID 号。如果服务器出现故 障或没有等待就关闭,那么分配给行的最后一个 ID 号与分配给行的下 一个 ID 号之间的最大间隔为 10 个编号:
create table mytable (
IdNum numeric (12,0) identity
)
with identity_gap = 10
示例 21 创建表 my_publishers,该表根据 state 列中的值按列表分区。有 关创建表分区的详细信息,请参见 《Transact-SQL 用户指南》。
create table my_publishers (
pub_id char (4) not null
, pub_name varchar (40) null
, city varchar (20) null
, state char (2) null
)
partition by list (state) (
west values ('CA', 'OR', 'WA') on seg1
, east values ('NY', 'MA') on seg2
)
示例 22 创建表 fictionsales,该表根据 date 列中的值按范围分区:
create table fictionsales (
store_id int not null
, order_num int not null
, date datetime not null
)
partition by range (date) (
q1 values <= ("3/31/2005") on seg1
, q2 values <= ("6/30/2005") on seg2
, q3 values <= ("9/30/2005") on seg3
, q4 values <= ("12/31/2005") on seg4
)
示例 23 创建表 currentpublishers,该表按循环分区:
|
pub_id |
char (4) |
not null |
|
|
, |
pub_name |
varchar (40) |
null |
|
, |
city |
varchar (20) |
null |
|
, |
state |
char (2) |
null |
|
pub_id |
char (4) |
not null |
|
|
, |
pub_name |
varchar (40) |
null |
|
, |
city |
varchar (20) |
null |
|
, |
state |
char (2) |
null |
create table currentpublishers (
)
partition by roundrobin 3 on (seg1)
示例 24 创建表 mysalesdetail,该表根据 ord_num 列中的值按散列分区:
|
store_id |
char (4) |
not |
null |
|
|
, |
ord_num |
varchar (20) |
not |
null |
|
, |
title_id |
tid |
not |
null |
|
, |
qty |
smallint |
not |
null |
|
, |
discount |
float |
not |
null |
|
store_id |
char (4) |
not |
null |
|
|
, |
ord_num |
varchar (20) |
not |
null |
|
, |
title_id |
tid |
not |
null |
|
, |
qty |
smallint |
not |
null |
|
, |
discount |
float |
not |
null |
create table mysalesdetail (
)
partition by hash (ord_num) ( p1 on seg1
, p2 on seg2
, p3 on seg3
)
示例 25 创建名为 mytitles 的表,该表具有一个实现计算列:
create table mytitles (
title_id tid not null
, title varchar (80) not null
, type char (12) not null
, pub_id char (4) null
, price money null
, advance money null
, total_sales int null
, notes varchar (200) null
, pubdate datetime not null
, sum_sales compute price * total_sales materialized
)
示例 26 创建一个员工表,该表具有一个可为空的加密列。 Adaptive Server 使用数据库缺省加密密钥来加密 ssn 数据:
|
ssn |
char(15) |
null |
|
|
encrypt |
name |
char(50) |
|
|
, deptid |
int |
|
ssn |
char(15) |
null |
|
|
encrypt |
name |
char(50) |
|
|
, deptid |
int |
create table employee_table (
)
示例 27 创建具有用于信用卡数据的加密列的客户表:
create table customer ( ccard char(16) unique
encrypt with cc_key
decrypt_default 'XXXXXXXXXXXXXXXX', name char(30)
)
ccard 列具有唯一约束并将 cc_key 用于加密。由于存在 decrypt_default 指 示符,当没有解密权限的用户选择 ccard 列时,Adaptive Server 将返回值 “XXXXXXXXXXXXXXXX”,而不是实际数据。
示例 28 创建一个表,该表将 description 指定为 300 字节长的行内 LOB 列,将 notes 指定为没有指定长度的行内 LOB 列 (继承行外存储的大 小),将 reviews 列指定为无论条件如何都在行外存储:
|
title_id |
tid |
not null |
|
|
, |
title |
varchar (80) |
not null |
|
, |
type |
char (12) |
null |
|
, |
price |
money |
null |
|
, |
pubdate |
datetime |
not null |
|
, |
description |
text |
in row (300) |
|
, |
notes |
text |
in row |
|
, |
reviews |
text |
off row |
|
title_id |
tid |
not null |
|
|
, |
title |
varchar (80) |
not null |
|
, |
type |
char (12) |
null |
|
, |
price |
money |
null |
|
, |
pubdate |
datetime |
not null |
|
, |
description |
text |
in row (300) |
|
, |
notes |
text |
in row |
|
, |
reviews |
text |
off row |
create table new_titles (
)
示例 29 在 pubs2 数据库的 order_seg 段中创建名为 orders 的虚拟散列表:
create table orders( id int
, age int
, primary key using clustered (id,age) = (10,1) with max 1000 key
)
on order_seg
数据布局为:
• order_seg 段开始于 ID 为 51200 的页。
• 第一个数据对象分配映射 (OAM) 页的 ID 为 51201。
• 每页的最大行数为 168。
• 行宽为 10。
• 溢出聚簇区域的根索引页为 51217。
图 1-1:示例的数据布局
页
|
(0, 0) ... (16, 7) |
|
|
(0, 0) ... (16, 7) |
|
51208
页
|
(16, 8) ... (33, 5) |
|
|
(16, 8) ... (33, 5) |
|
51209
页
51210
页
![]()
![]()
![]()
![]()
51211
|
(33, 6) ... (50, 3) |
|
|
(33, 6) ... (50, 3) |
|
(50, 4)
...
(67, 1)
根页
51217
页
|
(67, 2) ... (83, 9) |
|
|
(67, 2) ... (83, 9) |
|
51212
页
|
(84, 0) ... (99, 9) |
|
|
(84, 0) ... (99, 9) |
|
51213
页
51214
(100, 0)
...
(121, 7)
![]()
![]()
散列区域
![]()
![]()
溢出区域
示例 30 在 pubs2 数据库的 order_seg 段中创建名为 orders 的虚拟散列表:
create table orders(
id int default NULL
, age int
, primary key using
clustered (id,age) = (10,1) with max 100 key
, name varchar(30)
)
on order_seg
数据布局为:
• order_seg 段开始于 ID 为 51200 的页。
• 第一个数据 OAM 页的 ID 为 51201。
• 每页的最大行数为 42。
• 行宽为 45。
• 溢出聚簇区域的根索引页为 51217。
图 1-2:示例的数据布局
![]()
![]()
散列区域
页
![]()
51208
(0, 0, <name>)
...
(4, 1, <name>)
页
51209
(4, 2, <name>)
...
(8, 3, <name>)
页
51210
(4, 2, <name>)
...
(9, 9, <name>)
根页
51217
溢出区域
页
51211
(26, 6, <name>)
...
(93, 7, <name>)
用法 • create table 创建表和可选完整性约束。除非在 create table 语句中指 定了不同的数据库,否则将在当前打开的数据库中创建表。只要您 被列在 sysusers 表中并在数据库中具有 create table 权限,您就可以 在另一数据库中创建表或索引。
• 分配给表和索引的空间增量为一次 1 个扩充,或 8 页。每当一个扩 充填满后,就会分配另一个扩充。若要查看表所分配和使用的空间 量,请使用 sp_spaceused。
• 行内 Java 列的最大长度由根据表的方案、锁定风格和页大小决定的 可变长度列的最大大小决定。
• create table 在创建表之前会针对检查约束进行错误检查。
• 当从带有一个定义为 char (n) NULL 的列的 CIS 中使用 create table
时, CIS 会在远程服务器上将该列创建为 varchar (n)。
• 在索引列名后使用 asc 和 desc 关键字指定索引的排序顺序。通过创 建索引使各列按照在查询的 order by 子句中指定的顺序排列,可以 避免在查询处理过程中进行排序。
• 如果应用程序在 DOL 锁定表中插入短行,并且稍后对其进行更新 使得长度增加,则可使用 exp_row_size 减少将 DOL 锁定表中的行转 移到新位置的次数。
• at 关键字所提供的位置信息与 sp_addobjectdef 所提供的信息相同。 该信息存储在 sysattributes 表中。
限制
• 表中的最大列数取决于列的宽度和服务器的逻辑页大小:
• 列大小的总和不能超过服务器的逻辑页大小。
• 每个表的最大列数不能超过 1024。
• 所有页锁定表的最大可变长度列数是 254。
例如,如果服务器使用 2K 逻辑页大小,并且包括一个整数列 组成的表,则表中的最大列数将远远小于 1024。(1024 * 4 字节 超过了 2K 逻辑页大小。)
只要最大列数不超过 1024,就可以在单个表中混合使用可变长 度和固定长度的列。例如,如果服务器使用 8K 的逻辑页大小, 则为 APL 配置的表可以具有 254 个可为空值的整数列 (这些是 可变长度列)和 770 个不可为空值的整数列,共计 1024 列。
• 每个数据库最多可以有 2,000,000,000 个表,且每个表最多可以有
1024 个用户定义的列。每个表的行数仅受到可用存储的限制。
• 虽然 Adaptive Server 并不在下面的环境中创建表,当您执行 DML
操作时,将会收到关于大小限制的错误:
• 如果具有可变长度列的行的总行宽超出最大列大小
• 如果单个可变长度列的长度超出最大列大小
• 对于 DOL 锁定表,如果除初始列之外的任何可变长度列的偏移 量超出了 8191 字节的限制
• 如果所有固定长度列的总大小加上行开销大于表的锁定方案和页大 小允许的值,则 Adaptive Server 会报告错误。这些限制在 表 1-10 中 进行了说明。
表 1-10: 行和列的最大长度 – APL 和 DOL
|
锁定方案 |
页大小 |
最大行长度 |
最大列长度 |
|
APL 表 |
2K (2048 字节) |
1962 字节 |
1960 字节 |
|
4K (4096 字节) |
4010 字节 |
4008 字节 |
|
|
8K (8192 字节) |
8106 字节 |
8104 字节 |
|
|
16K (16384 字节) |
16298 字节 |
16296 字节 |
|
|
2K (2048 字节) |
1964 字节 |
1958 字节 |
|
|
4K (4096 字节) |
4012 字节 |
4006 字节 |
|
|
8K (8192 字节) |
8108 字节 |
8102 字节 |
|
|
16K (16384 字节) |
16300 字节 |
16294 字节 如果表不包含任何可变长度的列 |
|
|
16K (16384 字节) |
16300 (取决于 varlen 的最大 起始偏移 = 8191) |
8191-6-2 = 8183 字节 如果表至少包含一个可变长度列。 * |
|
|
*此大小包含六个字节的行开销和两个字节的行长度字段 |
|||
|
锁定方案 |
页大小 |
最大行长度 |
最大列长度 |
|
APL 表 |
2K (2048 字节) |
1962 字节 |
1960 字节 |
|
4K (4096 字节) |
4010 字节 |
4008 字节 |
|
|
8K (8192 字节) |
8106 字节 |
8104 字节 |
|
|
16K (16384 字节) |
16298 字节 |
16296 字节 |
|
|
2K (2048 字节) |
1964 字节 |
1958 字节 |
|
|
4K (4096 字节) |
4012 字节 |
4006 字节 |
|
|
8K (8192 字节) |
8108 字节 |
8102 字节 |
|
|
16K (16384 字节) |
16300 字节 |
16294 字节 如果表不包含任何可变长度的列 |
|
|
16K (16384 字节) |
16300 (取决于 varlen 的最大 起始偏移 = 8191) |
8191-6-2 = 8183 字节 如果表至少包含一个可变长度列。 * |
|
|
*此大小包含六个字节的行开销和两个字节的行长度字段 |
|||
DOL 表
• 每行的可变长度数据的最大字节数根据表的锁定方案而定:
|
页大小 |
最大行长度 |
最大列长度 |
|
2K (2048 字节) |
1962 |
1960 |
|
4K (4096 字节) |
4010 |
4008 |
|
8K (8192 字节) |
8096 |
8104 |
|
16K (16384 字节) |
16298 |
16296 |
DOL 表的最大列大小:
|
页大小 |
最大行长度 |
最大列长度 |
|
2K (2048 字节) |
1964 |
1958 |
|
4K (4096 字节) |
4012 |
4006 |
|
8K (8192 字节) |
8108 |
8102 |
|
16K (16384 字节) |
16300 |
16294 |
• 如果创建一个具有超过 8191 字节偏移量的可变长度列的 DOL 锁定 表,则您不能向该列添加任何行。
• 如果创建具有 varchar、 nvarchar、 univarchar 或 varbinary 列的表,而 列的总定义宽度大于所允许的最大行宽,则会出现一条警告消息, 但仍会创建该表。如果试图在这样的行中插入超过最大数量的字 节,或 update 某一行,使其总行宽大于最大长度,则 Adaptive Server 将产生一条错误消息,且命令失败。
• 当 create table 命令在 if...else 块或 while 循环中出现时, Adaptive Server 将在确定条件是否为真之前创建表模式。如果该表已经存 在,则会导致错误。为避免这种情况,要么确保数据库中不存在具 有相同名称的视图,要么按如下方式使用 execute 语句:
if not exists
(select * from sysobjects where name="my table")
begin
execute "create table mytable (x int)" end
• 不能用声明缺省值或检查约束执行 create table ,然后在同一批处理 或过程的表中插入数据。可以将创建和插入语句分放在两个不同的 批处理或过程中,或者使用 execute 分别执行操作。
• 不能在提供缺省值的 create table 语句中使用以下变量:
declare @p int select @p = 2
create table t1 (c1 int default @p, c2 int)
这样做将出现错误消息 154:“Variable is not allowed in default”。
• 虚拟散列表具有以下限制:
create proxy table、create table at remote server 或 alter table 当前不支持
SQL 用户定义的函数。
![]()
注释 注意:执行 SQL 函数需要使用语法 username.functionname()。
![]()
• 虚拟散列表的行必须唯一。虚拟散列表不允许多个行具有相同 的键列值,因为 Adaptive Server 不能将某行保留在散列区域 中,而将具有相同键列值的另一行保留在溢出聚簇区域中。
• 每个虚拟散列表都必须在排它段上创建。
创建压缩表
• 除非您另外声明,否则 Adaptive Server 会:
• 在您创建表时将数据压缩设置为 NULL。
• 在您修改数据时保留现有的压缩级别。
• 将所有分区都设置为在 create table 子句中指定的压缩级别。
• 您可以创建具有表级压缩的表,但保留某些分区不被压缩,这样您 便可以用活动分区的格式来维护非压缩数据,并定期根据情况压缩 数据。
• Adaptive Server 支持对所有形式的分区 (循环分区除外)进行分区 级压缩。
• 标记为 not compressed 的列不会被选择来进行行压缩或页压缩。不 过,行内列 (包括已实现的计算列)符合压缩条件:
• 所有短于 4 字节固定长度的数据都不符合行压缩条件。不过,
Adaptive Server 可以在页索引压缩期间压缩这些数据类型。
• 所有数据 (固定长度,或者等于或大于 4 字节的可变长度)都 符合行压缩条件。
• 缺省情况下, Adaptive Server 创建不压缩的非实现计算列。
• Adaptive Server 先压缩符合行级压缩条件的列。如果压缩的行比不 压缩的行长, Adaptive Server 会放弃压缩的行并将不压缩的行存储 到磁盘上,以确保压缩不浪费空间。
• 数据页可以同时包含压缩的数据行和不压缩的数据行。
• 您可以压缩固定长度的列。
• 您可以使用 with exp_row_size 子句仅为固定长度的行创建压缩 DOL
表。不能对所有页锁定 (APL) 表使用 with exp_row_size 子句。
• 如果您指定预期的行宽,但不压缩的行长度小于预期行宽,
Adaptive Server 将不压缩该行。
• 对某个表启用压缩后,对该表执行的所有 bcp 和 DML 操作都将压 缩数据。
• 压缩可能允许在页上存储更多行,但它不会更改表的最大行宽。不 过,它可以更改表的最小有效行宽。
• 对于可以进行行压缩或页索引压缩,但列的性质使得压缩不适用或 无意义的列 (例如,使用 bit 数据类型、加密的列,或时间戳列), 请使用 not compressed。
• 对表进行压缩不会压缩其索引。
有关压缩的限制
• 您不能压缩:
• 系统表
• 工作表
• 行内 Java 列
• 非实现计算列
• IDENTITY 列
• 为进行数据传输而添加的时间戳
• 所有数据类型;有关不支持的数据类型的列表,请参见 《压缩 用户指南》
• 加密列
• 如果最小行宽超过了所配置的锁定方案和页大小组合的最大用户数 据行宽,您就无法创建要进行压缩的表。例如,您无法创建一个仅 数据锁定表,其页大小为 2K,且包括数据类型为 char(2007) 的列 c1,因为它超过了最大用户数据行宽。对于行压缩和页压缩, Adaptive Server 会像对待新表一样执行行宽检查。
• 您不能创建一个具有短的、小于 4 字节的固定长度列的表来进行
row 或 page 压缩。
对使用大对象 (LOB) 数据的表进行压缩
压缩 LOB 表中的数据包括以下限制。您不能:
• 压缩计算文本列
• 对常规列的 XML 数据发出 LOB 压缩子句 (例如, lob_compression
=)
• 对系统表和工作表使用 LOB 压缩
列定义
• 基于用户定义的数据类型创建列时:
• 不能更改长度、精度或标度。
• 可以用 NULL 类型创建 NOT NULL 列,但不能创建 IDENTITY
列。
• 可以用 NOT NULL 类型创建 NULL 列或 IDENTITY 列 。
• 可以用 IDENTITY 类型创建 NOT NULL 列,但该列会继承
IDENTITY 属性。不能用 IDENTITY 类型创建 NULL 列。
• 只有具有可变长度数据类型的列才能存储 NULL 值。当创建具有固 定长度数据类型的 NULL 列时, Adaptive Server 会自动将其转换为 相应的可变长度数据类型。 Adaptive Server 不会向用户告知类型的 更改。
表 1-11 列出了固定长度数据类型及其可转换为的可变长度数据类 型。某些可变长度数据类型 (如 moneyn)是保留的数据类型,不 能用来创建列、变量或参数:
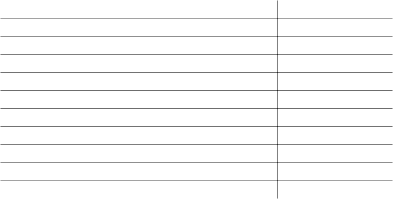
表 1-11: 用于存储 NULL 值的可变长度数据类型 原始的固定长度的数据类型 转换为
char varchar
nchar nvarchar
binary varbinary
datetime datetimn
float floatn
bigint、 int、 smallint、 tinyint intn unsigned bigint、 unsigned int、 unsigned smallint uintn decimal decimaln
numeric numericn
money 和 smallmoney moneyn
• 您可以通过两种方式创建列缺省值:通过在 create table 或 alter table 语句中将缺省值声明为列约束,或通过使用 create default 语句创建 缺省值并使用 sp_bindefault 将其绑定到列。
• 有关表及其列的报告,请执行系统过程 sp_help。
• 临时表存储在临时数据库 tempdb 中。
• 临时表名的前 13 个字符必须是每个会话唯一的。只有当前 Adaptive Server 会话才能访问这样的表。它们按名称后加上一个由系统提供 的数字后缀的方式存储在 tempdb..objects 中,并在当前会话结束时 或被显式删除时消失。
• 用 “tempdb..”前缀创建的临时表在 Adaptive Server 用户会话之间 是可共享的。仅当要在用户和会话间共享表时,才应使用 “tempdb..”前缀从存储过程内创建临时表。若要避免无意中共享临 时表,请在存储过程中创建和删除临时表时使用 “#”前缀。
• 在一个 Adaptive Server session 会话期间,临时表可由多个用户使 用。但是,通常不能确定特定的用户会话,因为临时表是用 “guest”用户 ID 2 创建的。如果多个用户运行创建临时表的过程, 每个用户都是一个 “guest”用户,这样 uid 值是一样的。因此,无 法得知临时表中的哪个用户会话是针对特定用户的。系统管理员可 以用 create login 向临时表中添加用户,在这种情况下,临时表中的 用户的会话可以使用各个 uid。
• 可将规则、缺省值和索引与临时表建立关联,但不能在临时表上创 建视图,或将触发器与之建立关联。
• 创建临时表时,仅当 tempdb..systypes 中存在要使用的用户定义数据 类型时才能使用该类型。要仅针对当前会话向 tempdb 添加用户定义 的数据类型,请在使用 tempdb 时执行 sp_addtype。若要永久性地添 加数据类型,应在使用 model 时执行 sp_addtype,然后重新启动 Adaptive Server,以将 model 复制到 tempdb 中。
• 表 “跟随”其聚簇索引。如果在一个段上创建表,然后在另一个段 上创建其聚簇索引,表将迁移到创建索引的段上。
• 如果段在单独的物理设备上,通过在一个段上创建表,并在另一个 段上创建其非聚簇索引可以加快插入、更新和选择的速度。请参见
《Transact-SQL 用户指南》中的 “使用聚簇或非聚簇索引”。
重命名表或表的列
• 使用 sp_rename 重命名表或列。
• 重命名表或其任一列后,使用 sp_depends 确定哪些过程、触发器和 视图依赖于该表,并重新定义这些对象。
![]()
警告!如果不重新定义这些依赖的对象, Adaptive Server 重新编译 后它们将无法使用。
![]()
定义完整性约束
• create table 语句通过一系列由 SQL 标准定义的完整性约束帮助控制数 据库的完整性。这些完整性约束子句限制用户可插入表中的数据。 您也可以用缺省值、规则、索引和触发器来强制实现数据库完整性。
完整性约束的优点表现在:在创建表的进程中一步完成完整性控件 的定义,并可简化创建这些完整性控件的过程。但是,与缺省值、 规则、索引和触发器相比,完整性约束的范围较为有限,并且综合 性也较差。
• 必须将对多列进行操作的约束声明为表级约束;将仅对一列进行操 作的约束声明为列级约束。列级约束和表级约束之间存在差异,但 用户很少会注意到这一差异。即,仅当修改列中的值时才会检查列 级约束;而如果对行进行任何修改,都会检查表级约束,而不管是 否更改了有关的列。
列级约束应放在列名和数据类型之后,分隔逗号之前 (请参见示例 5)。输入表级约束作为单独的逗号分隔子句 (请参见示例 4)。 Adaptive Server 对表级约束和列级约束的处理方式相同;二者的有 效程度相同。
• 可在表级或列级创建以下类型的约束:
• unique 约束不允许一个表中有两行在指定的列有相同的值。此 外, primary key 约束不允许列中有空值。
• 参照完整性 (references) 约束要求特定列中插入或更新的数据与 指定表和列中的数据相匹配。
• check 约束限制插入到列中的数据值。 也可通过以下方法来强制实现数据完整性:即限制在列中使用空值
(使用 null 或 not null 关键字);为列提供缺省值 (使用 default 子句)。
• 可以使用 sp_primarykey、 sp_foreignkey 和 sp_commonkey 在系统表中 保存信息,这样有助于阐明数据库中表之间的关系。这些系统过程 并不强制实现键关系或复制 create table 语句中的 primary key 和 foreign key 关键字的功能。若要获取已经定义的键的报告,请使用 sp_helpkey。若要获取常用连接的报告,请执行 sp_helpjoins。
• Transact-SQL 为强制实现完整性提供了几种机制。除了可在 create table 过程中声明的约束,您还可以创建规则、缺省值、索引和触发 器。 表 1-12 总结了完整性约束并介绍了强制实现完整性的其它方 法:
表 1-12: 强制实现完整性的方法

在 create table 中 其它方法
unique 约束 create unique index (在允许空值的列上)
primary key 约束 create unique index (在不允许空值的列上)
references 约束 create trigger
check 约束 (表级) create trigger
check 约束 (列级) create trigger 或 create rule 和 sp_bindrule
default 子句 create default 和 sp_bindefault
根据您的要求选择方法。例如,触发器对参照完整性 (如引用其它 列或对象)的处理方式比在 create table 中声明的方法更为复杂。此 外,由 create table 语句定义的约束是特定于该表的;与规则和缺省 值不同,不能将它们绑定到其它表,并且只能用 alter table 来对它们 进行删除或更改。即使在同一张表上,约束也不能包含子查询或集 合函数。
• create table 可包含很多约束,具有以下限制:
• unique 约束的数量受表可拥有的索引的数量的限制。
• 一个表只能有一个 primary key 约束。
• 表中每列只能包括一个 default 子句,但可以在同一列上定义不 同的约束。
例如:
create table discount_titles
(title_id varchar (6) default "PS7777" not null unique clustered
references titles (title_id) check (title_id like "PS%"),
new_price money)
新表 discount_titles 的列 title_id 是用各种完整性约束定义的。
• 可以创建错误消息并将它们绑定到参照完整性约束和 check 约束。 用 sp_addmessage 创建消息并用 sp_bindmsg 将它们绑定到约束。请 参见 sp_addmessage 和 sp_bindmsg。
• Adaptive Server 在强制实现参照约束前评估检查约束,并在强制实 现所有完整性约束后评估触发器。如果有任何约束失败, Adaptive Server 将取消数据修改语句,不会执行任何相关的触发器。但是, 违反约束并不 回退当前事务。
• 在被引用表中,不能更新与引用表中的值相匹配的列值或删除与引 用表中的值相匹配的行。首先在引用表中进行更新或删除,然后尝 试在被引用表中进行更新或删除。
• 在删除被参照表之前,必须先删除参照表;否则将违反约束。
• 有关为表定义的约束的信息,请使用 sp_helpconstraint。
唯一约束和主键约束
• 可在列级或表级声明 unique 约束。 unique 约束要求指定列中所有的 值都是唯一的。表中任意两行的指定列中不能有相同的值。
• primary key 约束是 unique 约束的限制性更强的形式。带有 primary key
约束的列不能包含空值。
![]()
注释 create table 语句的 unique 和 primary key 约束创建定义列的唯 一或主键属性的索引。sp_primarykey、sp_foreignkey 和 sp_commonkey 定义列间的逻辑关系。必须使用索引和触发器强制实现这些关系。
![]()
• 表级 unique 或 primary key 约束在 create table 语句中作为单独的项出 现,且必须包括所创建的表的一列或多列的名称。
• unique 或 primary key 约束在指定列上创建唯一索引。示例 3 中的
unique 约束创建了一个唯一的聚簇索引,与以下语句效果相同:
create unique clustered index salesind on sales (stor_id, ord_num)
只有索引名不同,通过命名约束可将其设置为 salesind。
• SQL 标准中的 unique 约束的定义规定,列定义不允许使用空值。缺 省情况下,如果在列定义中省略 null 或 not null,Adaptive Server 会将 列定义为不允许使用空值 (如尚未用 sp_dboption 进行更改)。在 Transact-SQL 中,可以将列定义为在 unique 约束下允许空值,因为 用于强制约束的唯一索引允许插入空值。
• 缺省情况下, unique 约束创建唯一的非聚簇索引;primary key 约束 创建唯一的聚簇索引。一个表只能有一个聚簇索引,所以只能指定 一个 unique clustered 或 primary key clustered 约束。
• create table 的 unique 和 primary key 约束提供了相对于 create index 语 句更简单的替代方法。然而:
• 不能创建非唯一索引。
• 不能使用所有由 create index 提供的选项。
• 必须使用 alter table drop constraint 删除这些索引。
参照完整性约束
• 参照完整性约束要求插入到定义约束的引用 表中的数据必须在被引 用 表中有匹配的值。参照完整性约束满足以下条件之一:
• 引用表的约束列中的数据包含空值。
• 引用表的约束列中的数据与被引用表中相应列的数据值匹配。
以 pubs2 数据库为例,插入到 salesdetail 表 (记录书的销售情况的 表)中的行必须在 titles 表中有一个有效的 title_id。salesdetail 是引用 表,而 titles 表是被引用表。现在, pubs2 使用触发器强制实现此参 照完整性。但是,salesdetail 表能够包括此列定义和参照完整性约束 来完成相同的任务:
title_id tid
references titles (title_id)
• 查询所允许的最大表引用数为 192。使用 sp_helpconstraint 可检查表 的参照约束。
• 表可以包括对其自身的参照完整性约束。例如, pubs3 中的 store_employees 表(列出了雇员及其管理者)在 emp_id 和 mgr_id 列 之间有以下自身引用:
emp_id id primary key, mgr_id id null
references store_employees (emp_id),
此约束确保所有的管理者也是雇员,且为所有的雇员都指派了有效 的管理者。
• 在删除引用表或删除参照完整性约束之前不能删除被引用表 (除非 该表仅包括一个对其自身的参照完整性约束)。
• Adaptive Server 并不为临时表强制实现参照完整性约束。
• 若要创建一个表,使其引用另一用户的表,必须对被引用表拥有
references 权限。有关指派 references 权限的信息,请参见 grant 命令。
• 表级参照完整性约束在 create table 语句中作为单独的项出现。它们 必须包括 foreign key 子句和一个或多个列名的列表。
只有在通过 primary key 约束将被引用表中的列指定为主键时,
references 子句中的列名才是可选的。
被引用列必须由该被引用表中的唯一索引约束。可以用 unique 约束 或 create index 语句创建该唯一索引。
• 引用表列的数据类型必须与被引用表列的数据类型匹配。例如,引 用表 (test_type) 中 col1 的数据类型与被引用表 (publishers) 中 pub_id 的数据类型相匹配:
create table test_type (col1 char (4) not null
references publishers (pub_id), col2 varchar (20) not null)
• 定义参照完整性约束时,被引用表必须存在。对于互相交叉引用的 表,使用 create schema 语句来同时定义两个表。作为替代方法,可 以创建一个不带约束的表,然后再使用 alter table 添加。有关详细信 息,请参见 create schema 或 alter table。
• create table 参照完整性约束提供了强制实现数据完整性的简单方 法。与触发器不同,约束不能:
• 对数据库中的相关表进行级联更改
• 通过引用其它列或数据库对象强制实施复杂限制
• 执行 “what-if”分析
当数据修改违反约束时,参照完整性约束并不回退事务。触发器允 许依据处理参照完整性的方式选择回退或继续事务。
![]()
注释 Adaptive Server 在检查触发器之前将检查参照完整性约束, 以使违反约束的数据修改语句也不会引发触发器。
![]()
使用跨数据库参照完整性约束
• 创建跨数据库约束时, Adaptive Server 会将以下信息存储在每个数 据库的 sysreferences 系统表中:
表 1-13: 存储的有关参照完整性约束的信息
|
存储在 sysreferences 中的信息 |
包含有关被引用表的信息的列 |
包含有关引用表的信息的列 |
|
键列 ID |
refkey1 到 refkey16 |
fokey1 到 fokey16 |
|
表 ID |
reftabid |
tableid |
|
数据库 ID |
pmrydbid |
frgndbid |
|
数据库名称 |
pmrydbname |
frgndbname |
• 可以删除引用表或其数据库。 Adaptive Server 自动从被引用数据库 中删除外键信息。
• 由于引用表依赖于来自被引用表的信息, Adaptive Server 不允许您:
• 删除被引用表,
• 删除包含被引用表的外部数据库,或者
• 使用 sp_renamedb 对其中任何一个数据库进行重命名。 必须使用 alter table 删除跨数据库约束后才能执行其中任一操作。
• 每次添加或删除跨数据库约束或者删除包含跨数据库约束的表时, 都请转储上述两个受影响的数据库。
![]()
警告!装载包含跨数据库约束的数据库的早期转储可能会导致数据 库损坏。
![]()
• sysreferences 系统表存储外部数据库的名称和 ID 号。如果您用 load database 更改数据库名或将其装载到其它服务器上,则 Adaptive Server 无法保证参照完整性。
![]()
警告!在转储数据库以便用不同数据库名装载或转移到另一个 Adaptive Server 之前,请使用 alter table 删除所有的外部参照完整性 约束。
![]()
check 约束
• check 约束可限制用户在表列中插入的值。 check 约束指定任何非空 值在插入到表之前必须通过的 search_condition。 search_condition 可 包括:
• 用 in 引入的一系列常量表达式
• 用 between 引入的一系列常量表达式
• 由 like 引入的一组条件,可以包含通配符
表达式可包括算术运算符和 Transact-SQL 内置函数。 search_condition 不能包含子查询、集合函数、主变量或参数。 Adaptive Server 并不为临时表强制实现 check 约束。
• 列级 check 约束只能引用定义它时所在的列,而不能引用表中的其 它列。表级 check 约束可引用表中的任何列。
• create table 允许在一个列定义中有多个 check 约束。
• check 完整性约束提供了使用规则和触发器的替代方法。它们特定 于被创建时所在的表,且不能绑定到其它表中的列或用户定义数据 类型。
• check 约束并不替换列定义。如果对允许空值的列声明 check 约束, 即使 search_condition 中不包含 NULL 值,也可以在列中显式或隐式 地插入 NULL 值。例如,如果创建了一个 check 约束在允许 NULL 值的表列上指定 “pub_id in ( “1389”、“0736”、“0877”、 “1622”、“1756”)”或 “@amount > 10000”,您仍可将 NULL 值 插入该列。列定义会替换 check 约束。
IDENTITY 列
• 首次向表中插入行时, Adaptive Server 为 IDENTITY 列指派值 1。 每个新行的列值都比上一个值增加 1。此值优先于在 create table 语 句中声明的或用 sp_bindefault 绑定到列的任何缺省值。
可插入 IDENTITY 列的最大值为数值 10 precision - 1。对于整数标 识,最大值为其类型的最大允许值 (例如对于 tinyint 为 255,对于 smallint 为 32767)。
请参见 《参考手册:过程》中的 第 1 章 “系统数据类型和用户定 义的数据类型”。
• 通过在 IDENTITY 列中插入值,可以指定该列的源值或恢复误删除 的行。对基表使用 set identity_insert table_name on 后,表的所有者、 数据库所有者或系统管理员可以显式地在 IDENTITY 列中插入值。 除非创建了 IDENTITY 列的唯一索引,否则 Adaptive Server 不会检 验值的唯一性。可以插入任何正整数。
• 如有必要,可用由表名限定的 syb_identity 关键字代替实际列名来引 用 IDENTITY 列。
• 系统管理员可使用 auto identity 数据库选项自动将 10 位的 IDENTITY
列包含在新表中。若要在数据库中打开此功能,请使用:
sp_dboption database_name, "auto identity", "true"
用户每次在数据库中创建表而不指定 primary 键、 unique 约束或 IDENTITY 列时,Adaptive Server 都会自动定义一个 IDENTITY 列。 用 select * 语句检索列时,此 SYB_IDENTITY_COL 列是不可见的。 必须在选择列表中显式地包含此列名。
• 服务器故障会使 IDENTITY 列值产生间隔。事务回退、删除行或手 动在 IDENTITY 列中插入数据也都会形成间隔。间隔的最大大小取 决于 identity burning set factor 和 identity grab size 配置参数的设置,或 者在 create table 或 select into 语句中给定的 identity_gap 值。请参见
《Transact-SQL 用户指南》的 “创建数据库和表”中的 “管理表中 的标识间隔”。
若要指定表的锁定方案,请使用关键字 lock 和以下锁定方案之一:
• 所有页锁定,锁定数据页和受查询影响的索引
• 数据页锁定,仅锁定数据页
• 数据行锁定,仅锁定数据行 如果没有指定锁定方案,将使用服务器的缺省锁定方案。使用配置参数
lock scheme 可设置服务器范围的缺省值。
可以使用 alter table 命令更改表的锁定方案。
空间管理属性
• 空间管理属性 fillfactor、 max_rows_per_page、 exp_row_size 和
reservepagegap 以下列方式帮助管理表的空间使用情况:
• fillfactor 在创建索引时在页上留出额外空间,但不会不断对
fillfactor 进行维护。
• max_rows_per_page 限制数据或索引页的行数。它的主要用途是 改善所有页锁定表的并发性,因为减少行数可减少锁争用。如 果指定 max_rows_per_page 值和 datapages 或 datarows 锁定,会 显示一条警告消息。表创建完毕,且值已存储在 sysindexes 中, 但仅当稍后将锁定方案更改为 allpages 时应用该值。
• exp_row_size 指定数据行的所需行宽。它仅适用于数据行,而不 适用于索引,且仅适用于具有可变长度列的仅数据锁定表。它 用于减少仅数据锁定表中的转移行的数量。主要是那些首次插 入时行具有空列或短列,但随后的更新又增加了这些列的大小 的表需要它。exp_row_size 在数据页上保留空间以供要增长到指 定大小的行使用。如果在创建所有页锁定表时指定了 exp_row_size,则会显示一条警告消息。表创建完毕,且值已存 储在 sysindexes 中,但仅当稍后将锁定方案更改为 datapages 或 datarows 时才应用该属性。
• reservepagegap 指定空白页与整页的比率以供执行扩展分配的命 令使用。它适用于所有锁定方案的数据和索引页。
• 表 1-14 显示了空间管理属性和锁定方案的有效组合。如果 create table 命令包括不兼容的组合,则会显示一条警告消息并创建表。值 存储在系统表中但不会应用。如果表的锁定方案的更改使这些属性 成为有效的,随后将使用它们。
表 1-14: 空间管理属性和锁定方案
|
属性 |
allpages |
datapages |
datarows |
|
max_rows_per_page |
可用 |
不可用 |
不可用 |
|
exp_row_size |
不可用 |
可用 |
可用 |
|
reservepagegap |
可用 |
可用 |
可用 |
|
fillfactor |
可用 |
可用 |
可用 |
• 表 1-15 显示了空间管理属性的缺省值和使用缺省值的效果。
表 1-15: 空间管理属性的缺省值和效果
|
属性 |
缺省值 |
使用缺省值的效果 |
|
max_rows_per_page |
0 |
使每页容纳尽可能多的行,最多可容纳 255 行 |
|
exp_row_size |
0 |
使用服务器范围的缺省值,该值使用配置参数 default exp_row_size percent 设置 |
|
reservepagegap |
0 |
在扩充分配期间不留下任何空白页 |
|
fillfactor |
0 |
完全填满叶页,在索引页上留有空间 |
使用 reservepagegap
• 使用大量空间的命令通过分配扩展而不是分配单页来分配新空间。 reservepagegap 关键字使这些命令留出空白页以使将来的页分配紧 邻被拆分的页或移走行的页发生。 表 1-16 显示了应用 reservepagegap 的时间。
表 1-16: 应用 reservepagegap 的情形
|
命令 |
应用于数据页 |
应用于索引页 |
|
快速 bcp |
是 |
如果存在索引,则不使用快速 bcp |
|
慢速 bcp |
仅用于堆表,不用于具有聚 簇索引的表 |
不执行扩充分配 |
|
select into |
是 |
目标表上不存在索引 |
|
是,对于聚簇索引 |
是 |
|
|
reorg rebuild |
是 |
是 |
|
alter table...lock (对于从所有页锁定到 DOL 锁定的 转换,或反向转换) |
是 |
是 |
• 表的 reservepagegap 值存储在 sysindexes 中并在对表执行以上任一操 作时使用。使用 sp_chgattribute 可更改存储的值。
• reservepagegap 不适用于工作表或对工作表的排序。
获取有关表的信息
• sp_help 显示关于表的信息,列出指派给指定表及其索引的任何属性
(如高速缓存绑定),给出属性的类、名称、整数值、字符值和注释。
• sp_depends 显示关于数据库中依赖于表的视图、触发器和过程的信息。
• sp_helpindex 报告有关为表创建的索引的信息。
• sp_helpartition 报告有关表的分区属性的信息。
创建带分区的表
• 创建带分区的表之前,必须准备好将用于分区的磁盘设备和段。
• 域分区取决于排序顺序。如果更改了排序顺序,则必须按照新排序 顺序对表重新分区。
• 域分区边界必须根据分区创建顺序升序排列。
• text、 unitext、 image 或 bit 类型、 Java 数据类型的列或计算列不能是 分区键的一部分,但分区表可以包含这些数据类型的列。组合分区 键最多可以包含 31 列。
• 对于域分区和散列分区,分区键可以是最多 31 个列的组合键。但 一般情况下,具有四个以上分区列的表会很难管理并且不很有用。
• 域分区和列表分区的边界值必须与对应分区键的数据类型兼容。如 果指定了兼容但属于不同数据类型的边界值, Adaptive Server 会将 该边界值转换为分区键的数据类型。 Adaptive Server 不支持:
• 显式转换。
• 导致数据丢失的隐式转换。
• 将 NULL 作为域分区表的边界。
• 从非二进制数据类型到 binary 或 varbinary 数据类型的转换。
• 可以在列表分区表的值列表中使用 NULL。
• 可以对包含 text 和 image 列的表分区,但分区不会影响 Adaptive Server 存储 text 和 image 列的方法,因为它们驻留在自己的分区上。
• 不能对远程表进行分区。
• Adaptive Server 将 NULL 视为比给定分区键列的任何其它分区键值小。
创建带计算列的表
• computed_column_expression 只能引用同一表中的列。
• computed_column_expression 的确定性属性对数据操作有显著影响。 请参见 《Transact-SQL 用户指南》中的 “确定性属性”。
• 计算列不能有缺省值,并且不能是 identity 或 timestamp 列。
• 只能为实现计算列指定可为空性。如果不指定可为空性,则所有计 算列缺省情况下都是可空的。虚拟计算列始终是可空的。
• 触发器和约束 (例如 check、 rule、 unique、 primary key 或 foreign key)仅支持实现计算列。不能将它们用于虚拟计算列。
• 如果计算列定义中用户定义的函数被删除或变为无效,则调用该函 数的任何计算列操作都会失败。
创建带加密列的表
• 可以对以下数据类型加密:
• int、 smallint、 tinyint
• unsigned int、 unsigned smallint、 unsigned tinyint
• bigint、 unsigned bigint
• decimal、 numeric
• float4、 float8
• money、 smallmoney
• date、 time、 smalldatetime、 datetime、 bigdatetime
• char、 varchar
• unichar、 univarchar
• binary、 varbinary
• bit
• 磁盘上的加密数据的基本数据类型为 varbinary。不会对空值加密。
• 如果您执行以下操作, create table 会显示错误:
• 基于引用一个或多个加密列的表达式来指定计算列。
• 将 encrypt 和 compute 参数用于相同的列。
• 在 partition 子句中列出加密列
• 在执行 create table、alter table 和 select into 操作的过程中, Adaptive Server 计算加密列的最大内部长度。在做出有关模式安排和页大小 的决策之前,数据库所有者必须知道加密列的最大长度。
• 如果指定加密密钥而未使用任何初始化矢量或随机填充,则可以创 建加密列的索引。如果加密列使用了初始化矢量或随机填充,则对 其执行 create index 命令时, Adpative Server 将显示错误。
• 在以下情况下,可以定义加密列的参照完整性约束:
• 加密引用的列和被引用的列。
• 用于对列执行加密的密钥指定 init_vector null,但您尚未指定 pad random。
• 不能加密计算列,并且加密列不能出现在定义计算列的表达式中。 您不能在 create table 的 partition_clause 中指定加密列。
请参见 《加密列用户指南》中的 “加密数据”。
创建虚拟散列表时的限制
• 您不能在包括虚拟散列表的段上使用 create table,因为虚拟散列表必 须仅采用一个排它段,而排它段是不能被其它表或数据库共享的。
• 虚拟散列表的行必须唯一。虚拟散列表不允许多个行具有相同的键 列值,因为 Adaptive Server 不能将某行保留在散列区域中,而将具 有相同键列的另一行保留在溢出聚簇区域中。
• 不支持 truncate table。应改用 delete from table_name。
• SQL92 不允许一个关系中的两个唯一约束具有相同的键列。但是, 虚拟散列表的主键子句不是标准的唯一约束,因此可以将具有相同 键列的单独唯一约束声明为虚拟散列键。
• 由于在创建表之后无法创建虚拟散列聚簇索引,因此也无法删除虚 拟散列聚簇索引。
• 必须在排它段上创建虚拟散列表。不能将指派给段用于创建虚拟散 列表的磁盘设备与其它段共享。
• 不能在同一排它段上创建两个虚拟散列表。 Adaptive Server 支持每 个数据库具有 32 个不同的段。缺省段、系统段和日志段这三个段
为保留段,所以每个数据库的最大虚拟散列表数为 29 个。
• 不能将 alter table 或 drop clustered index 命令用于虚拟散列表。
• 虚拟散列表必须使用所有页锁定。
• 虚拟散列表的键列和散列因子必须使用 int 数据类型。
• 虚拟散列表中不能包括 text 或 image 列,也不能包括数据类型基于
text 或 image 数据类型的列。
• 不能创建分区的虚拟散列表。
为内存数据库和宽松持久性数据库创建表
• 由 create table 定义的表级日志记录设置也适用于通过 select into 创建 的表。
• 虽然可在使用 full 持久性的数据库中创建具有最少日志记录的表, 但数据库不会对这些表使用最少记录。 Adaptive Server 允许您将这 些表设置为最少日志记录,以便于将这些数据库用作持久性设置为 no_recovery 的其它数据库的模板,其中最少记录在相关数据库中生 效。
确定 hash_factor 的值
可将第一个键的散列因子保持为 1。其余所有键列的散列因子大于散列 区域中允许的前一个键与其散列因子之乘积的最大值。
对于第一个键列的散列因子大于 1 的表, Adaptive Server 允许其页上具 有较少的行。例如,如果表的第一个键列的散列因子为 5,则在页上的 每一行之后,留给后四行的空间将保持为空。为了支持此功能, Adaptive Server 所需空间量为表空间的五倍。
如果键列的值大于或等于下一个键列的散列因子,会将当前行插入溢出 聚簇区域,以避免散列区域中出现冲突。
例如, t 是具有键列 id 和 age 并且对应的散列因子为 (10,1) 的虚拟散列 表。由于行 (5, 5) 和 (2, 35) 的散列值为 55,因此可能导致散列冲突。
但是,由于值 35 大于等于 10 (下一个键列 id 的散列因子),因此 Adaptive Server 会将第二行存储在溢出聚簇区域中,以避免散列区域中 出现冲突。
在另一个示例中,如果 u 是主索引和散列因子为 (id1, id2, id3) = (125, 25, 5) 并且 max hash_value 为 200 的虚拟散列表:
• 行 (1,1,1) 的散列值为 155,因此会将该行存储在散列区域中。
• 行 (2,0,0) 的散列值为 250,因此会将该行存储在溢出聚簇区域中。
• 行 (0,0,6) 的散列因子为 6 x 5,该值大于等于 25,因此会将该行存储 在溢出聚簇区域中。
• 行 (0,7,0) 的散列因子为 7 x 25,该值大于等于 125,因此会将该行存 储在溢出聚簇区域中。
对共享磁盘集群的限制
• 除了从同一本地临时数据库中的表之外,不能包括引用本地临时数 据库中的列的参照完整性约束。当 create table 尝试从其它数据库的 表中创建对本地临时数据库中列的引用时会失败。
• 除非包含列的表驻留在同一本地临时数据库中,否则您不能用本地 临时数据库中存储的加密密钥对该列加密。如果 alter table 尝试用本 地临时数据库中的加密密钥对列加密,而表位于其它数据库中,该 命令将失败。
Java-SQL 列
• 如果数据库中启用了 Java,则可创建具有 Java-SQL 列的表。有关详 细信息,请参见 Adaptive Server Enterprise 中的 Java。
• Java-SQL 列的声明类 (datatype) 必须使用 Serializable 或 Externalizable
接口。
• 创建表时,不能将 Java-SQL 列:
• 指定为外键
• 在 references 子句中指定
• 指定为具有 UNIQUE 属性
• 指定为主键
• 如果指定了 in row,那么根据数据库服务器的页大小和其它变量, 存储的值不能超过 16K 字节。
• 如果指定了 off row:
• 不能在检查约束中引用列。
• 不能在指定 distinct 的 select 中引用列。
• 不能在比较运算符、判定或 group by 子句中指定列。
标准 符合 ANSI SQL 的级别符合初级标准。
Transact-SQL 扩展包括:
• 使用数据库名限定表或列名
• IDENTITY 列
• not null 缺省值
• asc 和 desc 选项
• The reservepagegap 选项
• lock 子句
• on segment_name 子句
有关数据类型兼容的信息,请参见 《参考手册:构件块》中的第 1
章 “系统数据类型和用户定义的数据类型”。
权限 任何用户均可创建禁用记录的临时表和新表。 下文说明了基于您的细化权限设置的 create table 的权限检查。

细化权限已启用 在启用细化权限的情况下,您必须具有 create table 特权。您必须具有 create any table 特权才能为其他用户运行 create table。
细化权限已禁用 在禁用细化权限的情况下,您必须是数据库所有者、具有 sa_role 的用户或是 具有 create table 特权的用户。
审计 sysaudits 的 event 和 extrainfo 列中的值如下:

事件 审计选项 审计的命令或访问权限 extrainfo 中的信息
10 create create table • 角色 – 当前活动角色
• 关键字或选项 – NULL
• 先前值 – NULL
• 当前值 – NULL
• 其它信息 – NULL
• 代理信息 – set proxy 有效时的初始登录名
• 如果 with transfer table [on | off] 的 with 选项为:
• on – Adaptive Server 会在审计记录的额外信息中输出
WITH TRANSFER TABLE ON。
• off – Adaptive Server 会输出 WITH TRANSFER TABLE OFF。
另请参见 命令 alter table, create existing table, create index, create rule, create schema, create view, drop index, drop rule, drop table.
系统过程 sp_addmessage, sp_addsegment, sp_addtype, sp_bindmsg, sp_chgattribute, sp_commonkey, sp_depends, sp_foreignkey, sp_help, sp_helpjoins, sp_helpsegment, sp_primarykey, sp_rename, sp_spaceused.
Sybase SQL Anywhere数据库恢复工具ReadASADB:
之前就已经研发成功了能够从Sybase SQL Anywhere的DB文件中恢复数据的工具: ReadASADB。此工具支持ASA v5.0, v6.0, v7.0, v8.0, v9.0, v10.0, v11.0, v12.0, v16.0, v17.0等版本。
能够从损坏的SQL Anywhere数据文件(.db)和UltraLite数据文件(.udb)上提取数据的非常规恢复工具。
恢复Sybase SQL Anywhere的工具在国内处于领先水平。
Sybase SQL Anywhere数据库恢复工具ReadASADB功能
能够从损坏的SQL Anywhere数据文件(.db)和UltraLite数据文件(.udb)上提取数据的非常规恢复工具
- 适用于所有的SQL Anywhere版本 包括:5.x,6.x,7.x,8.x,9.x,10.x,11.x,12.x,16.x,17.x
- 适用于所有的UltraLite版本
- 能够恢复出来表结构和数据
- 能够恢复自定义数据类型
- 能够恢复存储过程等对象的语法
- 能够导出到目标数据库
- 能够导出到SQL文件并生成导入脚本
- 支持多种字符集,包括:cp850、cp936、gb18030、utf8等
- 能够恢复未加密或者简单加密类型的数据
- 简单易用
- 限制:不支持AES加密的数据文件
SQL Anywhere数据库非常规恢复工具ReadASADB使用介绍
Sybase SQL Anywhere数据库恢复工具ReadASADB适用场景
各种误操作:
- 误截断表(truncate table)
- 误删除表(drop table)
- 错误的where条件误删数据
- 误删除db或log文件
- 误删除表中的字段
Sybase SQL Anywhere数据库恢复工具ReadASADB的应用场景:
1.因为物理磁盘故障、操作系统、系统软件方面或者掉电等等原因导致的Sybase SQL Anywhere数据库无法打开的情况;
2.误操作,包括truncate table,drop table,不正确的where条件导致的误删除等;
Sybase SQL Anywhere无法打开时,比较常见的错误是:Assertion failed。
如:
1、Internal database error *** ERROR *** Assertion failed:201819 (8.0.1.2600) Checkpoint log: invalid bitmap page -- transaction rolled back
2、Internal database error *** ERROR *** Assertion failed:201819 (8.0.1.2600) Page number on page does not match page requested -- transaction rolled back
3、Internal database error *** ERROR *** Assertion failed:200502 (9.0.2.2451) Checksum failure on page 23 -- transaction rolled back
4、File is shorter than expected
5、Internal database error *** ERROR *** Assertion failed: 201116 Invalid free list index page found while processing checkpoint log -- transaction rolled back
6、*** ERROR *** Assertion failed: 51901 Page for requested record not a table page or record not present on page
7、*** ERROR *** Assertion failed: 201417 (7.0.4.3541) Invalid count or free space offset detected on a table page
8、Internal database error *** ERROR *** Assertion failed: 201425 (8.0.3.5594) Invalid count or free space offset detected on a free list page -- transaction rolled back.
9、Internal database error *** ERROR *** Assertion failed: 100702 (8.0.1.2600) Unable to modify indexes for a row referenced in rollback log -- transaction rolled back
Sybase ASE数据库恢复工具READSYBDEVICE:
一个不依赖数据库管理系统、直接从Sybase数据库设备文件上提取数据的业内领先的恢复工具!能够从损坏的Sybase ASE设备文件(.dat)上提取数据的非常规恢复工具。
Sybase ASE数据库恢复工具READSYBDEVICE的主要功能:
- 被勒索病毒加密数据文件及备份文件情况下的恢复;
- 系统崩溃只剩下数据文件的情况下的恢复,甚至数据库文件不存在而只有损坏的备份文件情况下的恢复;
- 因断电、硬盘坏道等造成数据库文件损坏情况下的恢复;
- delete数据恢复、误update数据恢复、误删除表(drop)恢复、误truncate表恢复 等;
- 各种Sybase内部系统表损坏、索引错误的修复;
- master数据库损坏而无法正常运行情况下的恢复;
- Sybase数据库被标记为可疑,不可用等情况的恢复;
- Sybase数据库中数据文件内部出现坏块情况下的恢复;
- Sybase数据库无数据文件但有日志文件的情况下的恢复;
- Sybase数据库只有数据文件无任何日志文件的情况下的恢复;
- Sybase数据文件被误删除情况下的碎片提取恢复;
- 磁盘阵列上的Sybase数据库被误格式化情况下的数据库恢复;
- 数据库sysobjects等系统表损坏无法正常应用情况下的恢复;
- Sybase数据库还原数据库出现失败情况下的恢复;
- Sybase数据库只剩下损坏的备份文件情况下的恢复。
Sybase ASE数据库恢复工具READSYBDEVICE支持的版本:
Sybase ASE 11.0.x,11.5.x,11.9.x,12.0.x,12.5.x,15.0.x,15.5.x,15.7.x,16.0.xSQL Server数据库恢复工具SQLRescue:
一个不依赖数据库管理系统、直接从SQL Server数据库文件上提取数据的业内领先的恢复工具!能够从损坏的SQL Server数据库文件(.mdf)上提取数据的非常规恢复工具。
SQL Server数据库恢复工具SQLRescue的主要功能:
- 系统崩溃只剩下数据文件的情况下的恢复,即无日志文件或者日志文件损坏情况下的恢复;
- 断电导致数据库文件损坏情况下的恢复;
- 硬盘坏道造成数据库损坏情况下的恢复;
- 数据文件内部存在坏页情况下的恢复;
- 企业管理器误删除数据表记录,管理软件误删除数据表记录的恢复;
- 并闩锁错误、格式化、误删除后导致软件不能使用的情况;
- 无法读取并闩锁页sysindexes失败情况下的修复;
- 数据文件被误删除情况下的碎片提取恢复;
- 系统表损坏、索引错误、误删除数据库表、删除记录的数据找回;
- master数据库损坏而无法正常运行情况下的恢复;
- 数据文件无法附加情况下的数据恢复;
- 数据库被标记为可疑,质疑,不可用等情况的恢复;
- 数据库sysobjects等系统表损坏情况下的恢复;
- 数据被误(drop、delete、truncate)删除表数据的恢复,误update后的数据恢复等;
- 还原时报一致性错误,错误823等情况下的数据恢复,各种错误提示的数据库文件修复;
- 数据库被误格式化等情况下的数据库恢复;
- 日志收缩造成数据库损坏情况下的恢复;
- 仅剩损坏的备份文件情况下的恢复。
SQL Server数据库恢复工具SQLRescue技术特点:
只要SQL Server数据库的数据文件存在,我们就有办法帮您从数据文件中找回重要数据。- 从数据文件中直接恢复数据
- 不能附加时直接恢复数据并生成新的数据库
- 系统表损坏的数据库修复
- 快速修复SQL 823错误、连接中断错误
SQL Server数据库恢复工具SQLRescue支持的版本:
Microsoft SQL Server 7.0, 2000, 2005, 2008, 2008R2, 2012, 2014, 2016, 2017,2019。+-------------------------------------华丽的分割线-------------------------------------------------------------------------
提供Sybase ASE及Sybase SQL Anywhere数据库修复服务,电话: 13811580958(微信),QQ: 289965371!We have many years of experience in recovering data from damanged Sybase devices. Contact us by Phone: +86 13811580958 Wechat: 13811580958 Email: 289965371@qq.com
京ICP备2020043699号-2
Powered by WordPress | SiteMap | Baidu Knows | Google Knows | About
