存档
window7程序兼容性助手基本上来说是没有用,国内的大部分软件都提示不兼容,但实际是兼容的,弄个这个只是多了麻烦浪费时间而已。
下面介绍4种关闭方法:
一 :打开 运行(热键:win+R)输入 gpedit.msc 打开 用户配置→ 管理模板→Windows组件→应用程序兼容性→ 关闭程序兼容性助理,设置成“已启用”
二 :计算机→管理→服务→ 禁用Program Compatibility Assistant Service服务
三 :点击“开始”,然后在“搜索框”中输入services.msc并回车。 现在滚动滚动条找到 Program Compatibility Assistant Service (程序兼容性助手服务),点击停止它。
或者执行:
sc stop PcsSvc
sc config PcsSvc start= disabled
四 : 若要禁用程序兼容性助手警告,使用测试计算机来确定要创建注册表项。 即可使用这些注册表项以禁用程序兼容性助手警告其他计算机上。 要这样做,请按下列步骤操作:
- 在测试计算机上运行在受影响的程序。
- 当收到程序兼容性助手警告消息时,单击以选中 不显示此消息再次 复选框。
请注意 此操作将以下注册表子项中创建一个注册表项:
HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows NT\CurrentVersion\AppCompatFlags项的名称是代表程序项 appcompat 数据库中的 GUID。 条目类型是 DWORD,并且该条目的值为 0x77。
请注意 程序兼容性助手运行仅为不会被阻止的程序出现警告。
- 退出程序。
- 请注意在步骤 3 中创建的注册表项。
- 在安装脚本包含在安装开始之前添加注册表项的步骤。
再次强调,我们不建议家庭用户禁用PCA,因为这会使得系统不稳定。然后,作为高级用户和管理员,将PCA关闭可以节约时间、避免懊恼的情况发生。
————————————————————————————————-
—- 本文为andkylee个人原创,请在尊重作者劳动成果的前提下进行转载;
—- 转载务必注明原始出处 : http://www.dbainfo.net
—- 关键字:win7 兼容性 禁止 AppCompatFlags PcsSvc
————————————————————————————————-
Powerbuilder历程
0引言
PowerBuilder是在中国用户群很大的数据库产品,多年来深受中国用户的喜爱。作为一个使用PowerBuilder多年进行系统开发的资深用 户,我在进行开发的同时,也关注着PowerBuilder的历史以及发展,以下是我对PowerBuilder历史的研究资料,希望能够给广大 PowerBuilder提供一点有用的东西。
本文的组织有两条主线,一是两任CEO对PowerBuilder发展的贡献;二是PowerBuilder产品线的发展。
从1974年Kertzman创建Powersoft公司的前身Computer Solutions公司,1984年Mark Hoffman创建SYBASE公司,到Computer Solutions公司易名为Powersoft公司,推出PowerBuilder1.0,再到1995年Powersoft公司和SYBASE公司的 合并,以及后来陈守宗拯救SYBASE公司,真实地展现了一个高科技公司从创建到发展壮大的过程。这样一个过程,绝对值得国内的高科技公司学习与借鉴。
1. 传奇的开始
·小说般的创业
说到PowerBuilder的创始人Mitchell E. Kertzman,的确是一个传奇人物。
Mitchell E. Kertzman出生在麻省的波士顿市,他曾经当过主席和CEO,他说“高科技企业的CEO生涯就象一本故事书”,事实上,他的CEO生涯就是一本故事书。
在十几岁时,Mitchell Kertzman是一位波士顿的民间歌手,1968年,当他在Brandeis University读二年级时,Mitchell Kertzman从大学辍学成为波士顿的WBCN 的摇滚电台主持人(这是美国最为激进的电台之一),并认为这将会成为他一生的职业。然而,1968年夏天他只在电台呆了4个月,就因为被指控煽动一场暴乱 ――和平抗议波士顿的宵禁(Mitchell Kertzman否认这项指控)而被电台解雇了。随后,他在加油站工作,不久,他的母亲在软件公司给他找了一份技术员的工作。从此,他开始了其编程生涯并 为之着迷,以至于后来创办了自己的软件公司。这听起来象一本小说里的故事,但对于Mitchell Kertzman来说,这是真实的。
Mitchell Kertzman平易近人,但很难预测他的行为。他曾经说过:“我年轻的时候非常害羞,但当我学会了弹吉他和唱民间歌曲,姑娘们喜欢上我了。”
商业世界艰难的开始
经过短暂的加油站工作,Mitchell Kertzman作为音频-视觉产品技术员,在一家名为“交互式学习系统”的教育软件公司工作。“我问主管我们部门的副总,我能否参与编程”,主管回答, “当然,你可以试试”。这成为Mitchell Kertzman一生很重要的决定。接下来四年里,Mitchell Kertzman开始为公司不停地编程。“我喜爱编程”,但令人啼笑皆非的是,现在SYBASE公司用Mitchell Kertzman的代码来告诫新的程序员们,如果他们写出这样的代码,那么就会滚蛋。
当公司陷入财政微机时,Kertzman开始了两项工作。一是通过邮件提供人体生理功能节律失调图表;二是给乐队提供预约服务。“这是一个本质上的错误,我竟然相信摇滚音乐家的商业道德”,Kertzman从中得到了宝贵的商业教训。
创建Powersoft公司
1974年Kertzman决定开始自己的编程事业,在其生活过的街区,麻省的West Newton街区,他创建了一个名为Computer Solutions的公司,这是一个制作MRP(生产需求计划)的小型软件咨询公司。当时创建这个公司时,Kertzman没有很多想法,只是“为食物而 编程”,为了养家糊口。他希望人们能够喜欢他编写的程序,这样他就可以买蔬菜和付房租。
Kertzman一直干得不错。他挂出招牌“定制程序”,其头两个客户都是制造业公司,Kertzman学习了其商业流程并将其自动化,使其易于使用,迅于实施。同时,Kertzman还非常注重软件用户界面的人机工程学,这样客户非常喜爱他编写的程序。
1987年,Kertzman看到了下一波计算热潮将是运行用户界面的网络PC,后来被称为客户/服务器计算市场的潜力,就开始寻找可以重写企业生产应用 的开发工具,但是没有找到,后来Kertzman就找到并雇用了Dave Litwack来开发这种新的开发工具,Litwack是Cullinet的前研发主管,对这个巨大的市场的开发工具有很好的构想,就是后来被称为 PowerBuilder的产品。于是他就开始了重写企业生产应用和研发开发工具的工作。开发工具的工作进展相当顺利,业务量也越来越大,所以 Kertzman卖掉了开发生产应用的业务。80年代末,他将公司改名为Powersoft,这曾是提供生产需求计划MRP的最好生产商之一。在1991 年6月,Powersoft公司发布了其旗标式客户/服务器应用开发工具,PowerBuilder1.0。
Powersoft公司随后还发布了Optima++,这是快速应用开发工具的一员,用来简化C++和Java的使用,并创建WINDOWS客户/服务器应用和WEB应用;S-Designor,设计和建模工具。
说到 PowerBuilder,不得不提到他的奠基人,David Litwack。
正是这位天才的程序员,一手缔造了伟大的开发工具,PowerBuilder。David Litwack在1990年代初的客户/服务器模式(client/server)热潮中,任职于 Powersoft公司时,他推动客户/服务器模式革命,倚仗的利器是“PowerBuilder”──他亲手开发的工具,当时最受欢迎的程序开发工具之 一。也因此David Litwack当上了Powersoft公司的主席。虽然Litwack后来离开Powersoft公司另谋生路,但是,他对Powersoft公司、对 客户/服务器模式的贡献都是不可磨灭的。
在局域网内不能ping通主机名。
如下:
C:\Documents and Settings\Administrator>ping win2003server
Ping request could not find host win2003server. Please check the name and try again.
解决办法:
网上邻居 右键 属性 ,在网络连接 窗口中选择本地连接 ,在本地连接点右键选择属性 ,选择Internet 协议(TCP/IP) ,再点属性 ,点高级 按钮,在弹出的高级TCP/IP设置 中切换到WINS 选项卡,如果NetBIOS设置 中禁用TCP/IP上的NetBIOS ,那么选择启用TCP/IP上的NetBIOS 即可解决问题。
C:\Documents and Settings\Administrator>ping win2003server
Pinging win2003server [192.168.2.176] with 32 bytes of data:
Reply from 192.168.2.176: bytes=32 time<1ms TTL=128
Reply from 192.168.2.176: bytes=32 time<1ms TTL=128
Reply from 192.168.2.176: bytes=32 time<1ms TTL=128
Reply from 192.168.2.176: bytes=32 time<1ms TTL=128
Ping statistics for 192.168.2.176:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 0ms, Maximum = 0ms, Average = 0ms
如果已经选择了启用TCP/IP上的NetBIOS,那么需要找其它解决办法了。
今天下午作为公司的代表参加了南大通用数据技术有限公司在钓鱼台国宾馆举行的GBase 8a产品发布会。GBase 8a是国内首款具有自主知识产权的分析型数据库。
GBase 8a采用了列式存储、智能查询、高效压缩、双向并行、自适应优化等多项新技术,打破了以往提高性能只能靠增加数据库的容量,建很多索引的常规,使得 GBase 8a既有高性能又有很高的数据压缩比。宣称查询速度比传统关系型统数据库能够提升10倍以上,有5倍以上的存储压缩率。现在发布的单节点GBase 8a可以支撑大约10T的数据量,紧接着会发布GBase 8a的集群版本SN(share nothing)能存储100T级别的大规模数据量。
发布会现场展示了GBase 8a的卓越的查询性能。 模拟一个超市历年的销售数据,2张表,每张都有500亿多行的记录。 统计一下表内的行总数select count(*) from TABLE_NAME 只花了2秒左右的时间。的确够快的!还有,在聚合统计方面的速度更惊人,统计1994年2月1日至1994年2月28日之间的折扣率为5%到7%之间的 (包含5%,7%)的所有销售收入总和,(忘记了还有一个也是范围的条件),查询列是: sum(数量*价格),这个操作仅仅需要了6秒多点的时间。很惊讶!国产数据库能做到这个水平,不容易。GBase 8a采用列存储,使用智能索引技术,有一个称为数据包或者知识网格knowledge grid的东西。想不出来,用什么技术会产生这么惊人的结果。
好像,GBase 8a目前只能运行在64bit的unix平台上。比较经典的是运行在linux上,比如redhat,redflag(这和他们的ceo以前在redflag工作过不无关系,呵呵)。 好像aix上也有版本吧。windows平台上应该不支持。
以后,继续试用。
来自:http://tech.sina.com.cn/it/2010-05-13/14374182429.shtml
--------------------------------------------------------------
导读:美国IT网站ComputerWorld今天撰文称,SAP收购Sybase的主要目的在于拓展移动商业应用领域,使得企业用户可以实现实时 决策。
以下为文章全文:
溢价收购
周三宣布斥资58亿美元收购Sybase后,SAP将未来的大赌注压在了移动商业应用领域。
SAP首席技术官维舍尔·斯卡(Vishal Sikka)在电话会议上说:“有了Sybase,我们将有机会大幅加速移动业务的发展。我们可以将SAP核心产品中的每个部分都分解开来,并面向移动领 域推出。当然,也包括SAP和Business Objects的分析产品。”
SAP周三晚些时候表示,该公司计划以每股65美元的价格收购Sybase。较Sybase过去三个月的平均股价溢价44%。
SAP预计,该交易有望于今年7月完成,此前还需要获得监管部门的审批以及足够多的Sybase股东支持。
拓展移动领域
从某些方面来看,Sybase仍然是最为知名的数据库企业,而SAP高管周三也讨论了有关Sybase IQ数据库的问题。该产品可以提升分析和数据仓储技术的性能。
但是Sybase还有许多产品被广泛用于部署智能手机或其他移动设备的商业应用,这似乎才是SAP真正感兴趣的东西。
“我们的许多用户,尤其是规模最大的用户,都试图实现企业的实时运营。但是当处于移动状态的员工手头没有数据进行实时决策时,就会变得非常困 难。”SAP联席CEO施杰翰(Jim Hagemann Snabe)说。
SAP将利用Sybase的移动应用平台,让企业员工可以通过各大移动设备平台访问SAP的商业和分析应用。“这将把车间与办公室连接起 来。”SAP另外一名联席CEO孟鼎铭(Bill McDermott)说。
斯卡表示,移动互联网“比桌面互联网大10倍”,而SAP认为“下一代企业员工将彻底连接并且完全处于移动状态”。他说,这一趋势在中国和印度 等新兴市场尤其明显。
斯卡说:“我们认为,世界将向移动方向发展,并将布满连接。”他认为,这一交易将对SAP的三元战略起到支持作用,包括企业预置(On- Premise)、按需随选(On-Demand)和移动应用(On-Device)。
不跟风甲骨文
SAP此前很少进行大规模并购。Sybase的交易是该公司历史上规模第二大的一起并购。仅次于2007年斥资68亿美元对数据分析厂商 Business Objects的收购。除此之外,SAP更倾向于通过规模较小的交易来获取一些无法快速自主研发的技术。
孟鼎铭表示,对Sybase的收购将拓展SAP现已确定的市场,并加速该公司的业务发展。
而作为SAP的主要竞争对手,甲骨文则借助大量的收购来拓展技术触角和用户基础。甲骨文的业务范围已经遍及数据库、应用、中间件、服务器和存储 器等各个技术领域。
SAP表示,该公司不会效仿这种方法。施杰翰说:“我们根本不认同这种全面开花的收购策略。我们认同用户的选择,并且专注于正确的领域。”
Sybase发展计划
施杰翰表示,Sybase今后将作为SAP的全资子公司运营,“使得该品牌能够兴旺繁荣”。但SAP不会将该公司的应用与Sybase联系起 来,也不会将其作为优先组合向用户推广。SAP的应用仍将对其他厂商的数据库一视同仁。
这很可能是明智之举。Sybase的Adaptive Server Enterprise(以下简称“ASE”)数据库目前并不是SAP用户的热门选择。根据美国市场研究公司Gartner的数据,该产品在全球数据库市场 仅占3.1%的份额。
事实上,ASE甚至无法支持所有的SAP应用,但这种情况现在可能会发生变化。SAP表示,该公司将利用内存(in-memory)技术来改进 ASE。该技术此前主要是被用于提升SAP的商业智能应用。
Sybase CEO程守宗(John Chen)将会加盟SAP并负责数据库部门,SAP还计划为其提供一个董事会席位。程守宗表示,尽管市场份额较小,但ASE在金融机构和股票交易所中却非 常受欢迎,而且Sybase过去5年间的收入保持了9%的年均增速。
咨询机构扬基集团(Yankee Group)认为这一交易对SAP而言至关重要。该公司称:“Sybase带来了一个移动平台,可以帮助SAP将应用转变成随时随地可以通过任何设备使用 的产品。这一点非常重要,可以帮助SAP保持竞争力。”
受到收购消息的刺激,Sybase股价周三下午飙升35%,盘后交易中又再度上涨15%,达到64.50美元,而周二的收盘价仅为41.57美 元。SAP股价周三则略有下滑,报收于44.55美元。(鼎宏)
------------------------------------------------------------------------------------------------------
PS:sap收购sybase,看重的是asa的移动数据库解决方案。sybase作为子公司独立运行,估计之前作为sybase子公司运行的 ianywhere会被改组成单独的比较重要的部门。sybase要是把全资子公司ianywhere卖给sap,sap一定太高兴了。但 是,sybase不可能傻到这种地步。
不知道IMDB这个ASE数据库能够多大程度上满足sap的应用?感觉对ase的前途不是很好。
IQ作为三驾马车中的之一,应该不会像ase那样受到亏待。
对于我们这些dba,虽然sybase目前的形势还不是太明朗,但是,感觉未必是坏事。
————————————————————————————————-
—- 本文为andkylee个人原创,请在尊重作者劳动成果的前提下进行转载;
—- 转载务必注明原始出处 : http://www.dbainfo.net
—- 关键字:收购 sybase SAP ASE ASA IQ 商业软件 auquire
————————————————————————————————-
据网易科技:2010-05-13 08:05:09
--------------------------------
5月13日消息,据国外媒体报道,德国软件巨擘SAP周三宣布,将以58亿美元的现金收购Sybase
SAP将以每股65美元的价格收购Sybase,交易总金额为58亿美元。自20世纪90年代中期以来,Sybase股价从未超过50 美元。
SAP是全球最大的商业管理软件厂商,而Sybase是全球领先的数据管理及企业集成解决方案供应商,该交易将有助于SAP与甲骨文抗衡。甲骨文不 久前以74亿美元收购Sun。
SAP表示,该交易将使SAP获得Sybase的核心技术,使一些商业应用在手机上运行。如果顺利,该交易预计于今年第三季度完成。
在交易宣布前,市场上已经有相关传闻,导致Sybase股价上扬35%至56.14美元。在盘后交易中,Sybase股价再度上扬15%至 64.30美元。
from AP,May 12, 2010
---------------------
SOFTWARE SNAP-UP: German business software maker SAP AG is buying Sybase Inc . for $5.8 billion. Sybase makes database software and technology that connects business applications to mobile phones.
ATTACKING ORACLE: SAP is muscling in to more of Oracle Corp .'s database turf with the deal. Oracle has spent $40 billion since 2004 on acquisitions, mostly to buy its way into markets where SAP is strong.
BIG MOVE FOR NEW BOSSES: The acquisition is the first big move by SAP's new co-CEOs Bill McDermott and Jim Hagemann Snabe, who took over in February after the previous CEO resigned.
Copyright 2010 The Associated Press. All rights reserved. This material may not be published, broadcast, rewritten, or redistributed.
哎!sybase从09年下半年在国内刚开始起色,怎么又被卖了呢?本来还打算最近考个sybase认证的。看来得推迟或者取消了。
在新的电脑上安装完Vmware Server2.0.2后,导入以前的虚拟机文件。在左边的虚拟机列表中选中虚拟机后,右边的窗口空白一片, 无法查看虚拟机的配置信息也无法启动虚拟机。
在系统日志看,看到如下内容:
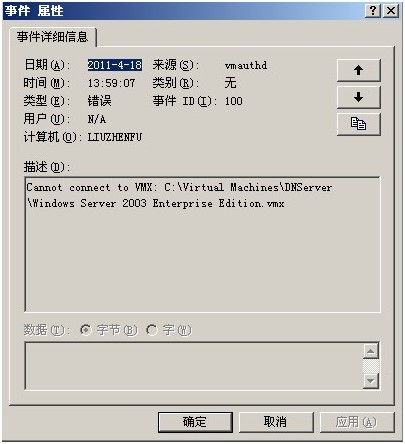
然后到目录:C:\Documents and Settings\All Users\Application Data\VMware\VMware Server下查看虚拟机的日志信息。依次查看hostd-0.log到hostd-9.log日志文件的内容。
发现如下比较重要的信息:
[2011-04-17 00:46:37.859 'Solo' 1264 info] VM inventory configuration: C:\Documents and Settings\All Users\Application Data\VMware\VMware Server\hostd\vmInventory.xml
[2011-04-17 00:46:37.875 'VmMisc' 1264 info] Max supported virtual machines: 512
[2011-04-17 00:46:37.890 'Vmsvc' 1264 info] Foundry_CreateEx failed: Error: (4000) The virtual machine cannot be found
[2011-04-17 00:46:37.890 'vm:I:\virtual-systems\RedHat5.4\Red Hat Enterprise Linux 5.vmx' 1264 info] Failed to load virtual machine.
[2011-04-17 00:46:37.890 'vm:I:\virtual-systems\RedHat5.4\Red Hat Enterprise Linux 5.vmx' 1264 info] Failed to load virtual machine. Marking as unavailable: vim.fault.NotFound
[2011-04-17 00:46:37.890 'vm:I:\virtual-systems\RedHat5.4\Red Hat Enterprise Linux 5.vmx' 1264 warning] Failed to find activation record, event user unknown.
[2011-04-17 00:46:37.890 'ha-eventmgr' 1264 info] Event 1 : Configuration file for on liuzhenfu in ha-datacenter cannot be found
[2011-04-17 00:46:37.906 'PropertyProvider' 1264 verbose] RecordOp ASSIGN: latestEvent, ha-eventmgr
[2011-04-17 00:46:37.906 'vm:I:\virtual-systems\RedHat5.4\Red Hat Enterprise Linux 5.vmx' 1264 info] State Transition (VM_STATE_INITIALIZING -> VM_STATE_INVALID_LOAD)
[2011-04-17 00:46:37.906 'PropertyProvider' 1264 verbose] RecordOp ASSIGN: disabledMethod, 112
[2011-04-17 00:46:37.906 'vm:I:\virtual-systems\RedHat5.4\Red Hat Enterprise Linux 5.vmx' 1264 info] Marking VirtualMachine invalid
[2011-04-17 00:46:37.906 'PropertyProvider' 1264 verbose] RecordOp ASSIGN: disabledMethod, 112
[2011-04-17 00:46:37.906 'PropertyProvider' 1264 verbose] RecordOp ASSIGN: runtime.connectionState, 112
[2011-04-17 00:46:37.906 'PropertyProvider' 1264 verbose] RecordOp ASSIGN: summary.runtime.connectionState, 112
[2011-04-17 00:46:37.906 'Vmsvc' 1264 info] Loaded virtual machine: I:\virtual-systems\RedHat5.4\Red Hat Enterprise Linux 5.vmx
[2011-04-17 00:46:37.906 'PropertyProvider' 1264 verbose] RecordOp ASSIGN: childConfiguration, ha-root-pool
[2011-04-17 00:46:37.906 'PropertyProvider' 1264 verbose] RecordOp ADD: vm["112"], ha-root-pool
[2011-04-17 00:46:37.906 'PropertyProvider' 2440 verbose] RecordOp ASSIGN: summary.runtime, ha-root-pool
[2011-04-17 00:46:38.203 'Libs' 1848 info] Reloading config state: D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmx
[2011-04-17 00:46:38.546 'Libs' 1848 info] VMHS: Transitioned vmx/execState/val to poweredOff
[2011-04-17 00:46:38.687 'Libs' 2128 info] CnxAuthdConnect: Returning false because CnxAuthdConnectPipe failed
[2011-04-17 00:46:38.687 'Libs' 2128 info] CnxConnectAuthd: Returning false because CnxAuthdConnect failed
[2011-04-17 00:46:38.687 'Libs' 2128 info] Cnx_Connect: Returning false because CnxConnectAuthd failed
[2011-04-17 00:46:38.687 'Libs' 2128 info] Cnx_Connect: Error message: Failed to read vmware-authd port number: Cannot connect to VMX: D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmx
[2011-04-17 00:46:38.687 'vm:D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmx' 1264 info] Upgrade is required for virtual machine, version: 4
[2011-04-17 00:46:38.843 'DiskLib' 1264 info] DISKLIB-SPARSECHK: [D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmdk] 16384 excess bytes at end of file
[2011-04-17 00:46:38.875 'DiskLib' 1264 info] DISKLIB-SPARSECHK: [D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmdk] GT Error (EE): GT[46][271] = 6814336 / 6814336
[2011-04-17 00:46:38.875 'DiskLib' 1264 info] DISKLIB-SPARSECHK: [D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmdk] Resolving GT[46][271] = 0
[2011-04-17 00:46:38.875 'DiskLib' 1264 info] DISKLIB-SPARSECHK: [D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmdk] GT Error (EE): GT[46][272] = 6814464 / 6814464
[2011-04-17 00:46:38.875 'DiskLib' 1264 info] DISKLIB-SPARSECHK: [D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmdk] Resolving GT[46][272] = 0
[2011-04-17 00:46:38.875 'DiskLib' 1264 info] DISKLIB-SPARSECHK: [D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmdk] GT Error (EE): GT[46][273] = 6814592 / 6814592
[2011-04-17 00:46:38.875 'DiskLib' 1264 info] DISKLIB-SPARSECHK: [D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmdk] Resolving GT[46][273] = 0
[2011-04-17 00:46:38.875 'DiskLib' 1264 info] DISKLIB-SPARSECHK: [D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmdk] GT Error (EE): GT[46][274] = 6814720 / 6814720
[2011-04-17 00:46:38.875 'DiskLib' 1264 info] DISKLIB-SPARSECHK: [D:\Virtual Machines\Node1\Windows Server 2003 Enterprise Edition.vmdk] Resolving GT[46][274] = 0
在另外一个日志文件中发现:
[2011-04-18 13:59:07.281 'Libs' 2204 info] CnxConnectAuthd: Returning false because CnxAuthdConnect failed
[2011-04-18 13:59:07.281 'Libs' 2204 info] Cnx_Connect: Returning false because CnxConnectAuthd failed
[2011-04-18 13:59:07.281 'Libs' 2204 info] Cnx_Connect: Error message: Failed to read vmware-authd port number: Cannot connect to VMX: C:\Virtual Machines\DNServer\Windows Server 2003 Enterprise Edition.vmx
[2011-04-18 13:59:07.281 'vm:C:\Virtual Machines\DNServer\Windows Server 2003 Enterprise Edition.vmx' 2900 info] Upgrade is required for virtual machine, version: 4
[2011-04-18 13:59:07.671 'PropertyProvider' 2900 verbose] RecordOp ASSIGN: summary, 64
[2011-04-18 13:59:07.671 'vm:C:\Virtual Machines\DNServer\Windows Server 2003 Enterprise Edition.vmx' 2900 info] State Transition (VM_STATE_INITIALIZING -> VM_STATE_OFF)
在网上寻找了很久,这篇博文解决VMWare Server 2.0 出现 Cannot Connect to VMX的问题的方法也不奏效。而且,vmware社区http://communities.vmware.com/index.jspa的很多帖子也没有给出有效的方法。这个Cannot connect to VMX问题也是个比较棘手的问题。
解决方法:原来我犯了一个低级的错误。曾经下载了vmware server 1.0.6 和 vmware server 2.0.2这2个版本的安装程序。因为以前的虚拟机环境不存在了,在新的电脑上安装的时候,就选择了vmware server 2.0.2。出现了上面的问题,曾经还重装了两次。 最后看了一篇自己曾经写过的文档《在VMServer1.0.6中配置SQL Server 2005故障转移群集》,才意识到自己选错vmware的版本了。多么低级的一个错误啊,白白折腾了一天多的时间。
曾经还出现过如下的无法登录的问题:The server was unable to process your log in request.Please check with your server administrator.
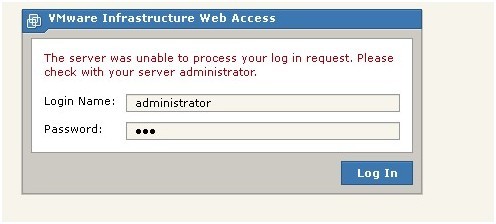
解决方法:设置使得登录用户对虚拟机文件所在的目录拥有权限。
大端(Big Endian)与小端(Little Endian)简介
///////////////////////////////////////////////////////
1. 你从哪里来?
端模式(Endian)的这个词出自Jonathan Swift书写的《格列佛游记》。这本书根据将鸡蛋敲开的方法不同将所有的人分为两类,从圆头开始将鸡蛋敲开的人被归为Big Endian,从尖头开始将鸡蛋敲开的人被归为Littile Endian。小人国的内战就源于吃鸡蛋时是究竟从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。在计算机业Big Endian和Little Endian也几乎引起一场战争。在计算机业界,Endian表示数据在存储器中的存放顺序。采用大端方式 进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。下文举例说明在计算机中大小端模式的区别。
//////////////////////////////////////////////////////
2. 读书百遍其义自见
小端口诀: 高高低低 -> 高字节在高地址, 低字节在低地址
大端口诀: 高低低高 -> 高字节在低地址, 低字节在高地址
long test = 0x313233334;
小端机器:
低地址 --> 高地址
00000010: 34 33 32 31 -> 4321
大端机器:
低地址 --> 高地址
00000010: 31 32 33 34 -> 4321
test变量存储的是的0x10这个地址,
那编译器怎么知道是读四个字节呢? -> 根据变量test的类型long可知这个变量占据4个字节.
那编译器怎么读出这个变量test所代表的值呢? -> 这就根据是little endian还是big endian来读取
所以, 小端, 其值为0x31323334; 大端, 其值为0x34333231
htonl(test) 的情况: ->其值为: 0x34333231
小端机器:
00000010: 31 32 33 34 -> 1234
大端机器:
00000010: 34 33 32 31 -> 4321
/////////////////////////////////////////////////////////////////////////////////////
3. 拿来主义
Byte Endian是指字节在内存中的组织,所以也称它为Byte Ordering,或Byte Order。
对于数据中跨越多个字节的对象, 我们必须为它建立这样的约定:
(1) 它的地址是多少?
(2) 它的字节在内存中是如何组织的?
针对第一个问题,有这样的解释:
对于跨越多个字节的对象,一般它所占的字节都是连续的,它的地址等于它所占字节最低地址。(链表可能是个例外, 但链表的地址可看作链表头的地址)。
比如: int x, 它的地址为0x100。 那么它占据了内存中的Ox100, 0x101, 0x102, 0x103这四个字节(32位系统,所以int占用4个字节)。
上面只是内存字节组织的一种情况: 多字节对象在内存中的组织有一般有两种约定。 考虑一个W位的整数。
它的各位表达如下:[Xw-1, Xw-2, ... , X1, X0],它的
MSB (Most Significant Byte, 最高有效字节)为 [Xw-1, Xw-2, ... Xw-8];
LSB (Least Significant Byte, 最低有效字节)为 [X7,X6,..., X0]。
其余的字节位于MSB, LSB之间。
LSB和MSB谁位于内存的最低地址, 即谁代表该对象的地址?
这就引出了大端(Big Endian)与小端(Little Endian)的问题。
如果LSB在MSB前面, 既LSB是低地址, 则该机器是小端; 反之则是大端。
DEC (Digital Equipment Corporation,现在是Compaq公司的一部分)和Intel的机器(X86平台)一般采用小端。
IBM, Motorola(Power PC), Sun的机器一般采用大端。
当然,这不代表所有情况。有的CPU即能工作于小端, 又能工作于大端, 比如ARM, Alpha,摩托罗拉的PowerPC。 具体情形参考处理器手册。
具体这类CPU是大端还是小端,应该和具体设置有关。
(如,Power PC支持little-endian字节序,但在默认配置时是big-endian字节序)
一般来说,大部分用户的操作系统(如windows, FreeBsd,Linux)是Little Endian的。少部分,如MAC OS ,是Big Endian 的。
所以说,Little Endian还是Big Endian与操作系统和芯片类型都有关系。因此在一个处理器系统中,有可能存在大端和小端模式同时存在的现象。这一现象为系统的软硬件设计带来了不小的 麻烦,这要求系统设计工程师,必须深入理解大端和小端模式的差别。大端与小端模式的差别体现在一个处理器的寄存器,指令集,系统总线等各个层次中。
Linux系统中,你可以在/usr/include/中(包括子目录)查找字符串BYTE_ORDER(或
_BYTE_ORDER, __BYTE_ORDER),确定其值。BYTE_ORDER中文称为字节序。这个值一般在endian.h或machine/endian.h文件中可以找到,有时在feature.h中,不同的操作系统可能有所不同。
【用函数判断系统是Big Endian还是Little Endian】
enum {FALSE = 0, TRUE = !FALSE};
typedef short BOOL;
BOOL IsBig_Endian()
//如果字节序为big-endian,返回true;
//反之为 little-endian,返回false
{
unsigned short test = 0x1122;
if(*( (unsigned char*) &test ) == 0x11)
return TRUE;
else
return FALSE;
}//IsBig_Endian()
//////////////////////////////////////////////////////////////////////////////
可以做个实验
在windows上下如下程序
#include <stdio.h>
#include <assert.h>
void main( void )
{
short test;
FILE* fp;
test = 0x3132; //(31ASIIC码的’1’,32ASIIC码的’2’)
if ((fp = fopen ("c:\\test.txt", "wb")) == NULL)
assert(0);
fwrite(&test, sizeof(short), 1, fp);
fclose(fp);
}
然后在C盘下打开test.txt文件,可以看见内容是21,而test等于0x3132,可以明显的看出来x86的字节顺序是低位在前.如果我们把这段 同样的代码放到(big-endian)的机器上执行,那么打出来的文件就是12.这在本机中使用是没有问题的.但当你把这个文件从一个big- endian机器复制到一个little-endian机器上时就出现问题了.
如上述例子,我们在big-endian的机器上创建了这个test文件,把其复制到little-endian的机器上再用fread读到一个 short里面,我们得到的就不再是0x3132而是0x3231了,这样读到的数据就是错误的,所以在两个字节顺序不一样的机器上传输数据时需要特别小 心字节顺序,理解了字节顺序在可以帮助我们写出移植行更高的代码.
正因为有字节顺序的差别,所以在网络传输的时候定义了所有字节顺序相关的数据都使用big-endian,BSD的代码中定义了四个宏来处理:
#define ntohs(n) //网络字节顺序到主机字节顺序 n代表net, h代表host, s代表short
#define htons(n) //主机字节顺序到网络字节顺序 n代表net, h代表host, s代表short
#define ntohl(n) //网络字节顺序到主机字节顺序 n代表net, h代表host, s代表 long
#define htonl(n) //主机字节顺序到网络字节顺序 n代表net, h代表host, s代表 long
举例说明下这其中一个宏的实现:
#define sw16(x) \
((short)( \
(((short)(x) & (short)0x00ffU) << ![]() | \
| \
(((short)(x) & (short)0xff00U) >> ![]() ))
))
这里实现的是一个交换两个字节顺序.其他几个宏类似.
我们改写一下上面的程序
#include <stdio.h>
#include <assert.h>
#define sw16(x) \
((short)( \
(((short)(x) & (short)0x00ffU) << ![]() | \
| \
(((short)(x) & (short)0xff00U) >> ![]() ))
))
#define sw32(x) \
((long)( \
(((long)(x) & (long)0x000000ff) << 24) | \
(((long)(x) & (long)0x0000ff00) << ![]() | \
| \
(((long)(x) & (long)0x00ff0000) >> ![]() | \
| \
(((long)(x) & (long)0xff000000) >> 24) ))
// 因为x86下面是低位在前,需要交换一下变成网络字节顺序
#define htons(x) sw16(x)
#define htonl(x) sw32(x)
void main( void )
{
short test;
FILE* fp;
test = htons(0x3132); //(31ASIIC码的’1’,32ASIIC码的’2’)
if ((fp = fopen ("c:\\test.txt", "wb")) == NULL)
assert(0);
fwrite(&test, sizeof(short), 1, fp);
fclose(fp);
}
如果在高字节在前的机器上,由于与网络字节顺序一致,所以我们什么都不干就可以了,只需要把#define htons(x) sw16(x)宏替换为 #define htons(x) (x).
一开始我在理解这个问题时,总在想为什么其他数据不用交换字节顺序?比如说我们write一块buffer到文件,最后终于想明白了,因为都是unsigned char类型一个字节一个字节的写进去,这个顺序是固定的,不存在字节顺序的问题
【大端(Big Endian)与小端(Little Endian)简介】
Byte Endian是指字节在内存中的组织,所以也称它为Byte Ordering,或Byte Order。
对于数据中跨越多个字节的对象, 我们必须为它建立这样的约定:
(1) 它的地址是多少?
(2) 它的字节在内存中是如何组织的?
针对第一个问题,有这样的解释:
对于跨越多个字节的对象,一般它所占的字节都是连续的,它的地址等于它所占字节最低地址。(链表可能是个例外, 但链表的地址可看作链表头的地址)。
比如: int x, 它的地址为0x100。 那么它占据了内存中的Ox100, 0x101, 0x102, 0x103这四个字节(32位系统,所以int占用4个字节)。
上面只是内存字节组织的一种情况: 多字节对象在内存中的组织有一般有两种约定。 考虑一个W位的整数。
它的各位表达如下:[Xw-1, Xw-2, ... , X1, X0],它的
MSB (Most Significant Byte, 最高有效字节)为 [Xw-1, Xw-2, ... Xw-8];
LSB (Least Significant Byte, 最低有效字节)为 [X7,X6,..., X0]。
其余的字节位于MSB, LSB之间。
LSB和MSB谁位于内存的最低地址, 即谁代表该对象的地址?
这就引出了大端(Big Endian)与小端(Little Endian)的问题。
如果LSB在MSB前面, 既LSB是低地址, 则该机器是小端; 反之则是大端。
DEC (Digital Equipment Corporation,现在是Compaq公司的一部分)和Intel的机器(X86平台)一般采用小端。
IBM, Motorola(Power PC), Sun的机器一般采用大端。
当然,这不代表所有情况。有的CPU即能工作于小端, 又能工作于大端, 比如ARM, Alpha,摩托罗拉的PowerPC。 具体情形参考处理器手册。
具体这类CPU是大端还是小端,应该和具体设置有关。
(如,Power PC支持little-endian字节序,但在默认配置时是big-endian字节序)
一般来说,大部分用户的操作系统(如windows, FreeBsd,Linux)是Little Endian的。少部分,如MAC OS ,是Big Endian 的。
所以说,Little Endian还是Big Endian与操作系统和芯片类型都有关系。
Linux系统中,你可以在/usr/include/中(包括子目录)查找字符串BYTE_ORDER(或
_BYTE_ORDER, __BYTE_ORDER),确定其值。BYTE_ORDER中文称为字节序。这个值一般在endian.h或machine/endian.h文件中可以找到,有时在feature.h中,不同的操作系统可能有所不同。
big endian是指低地址存放最高有效字节(MSB),而little endian则是低地址存放最低有效字节(LSB)。
用文字说明可能比较抽象,下面用图像加以说明。比如数字0x12345678在两种不同字节序CPU中的存储顺序如下所示:
Big Endian
低地址 高地址
----------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 12 | 34 | 56 | 78 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Little Endian
低地址 高地址
----------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 78 | 56 | 34 | 12 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
从上面两图可以看出,采用big endian方式存储数据是符合我们人类的思维习惯的.
为什么要注意字节序的问题呢?你可能这么问。当然,如果你写的程序只在单机环境下面运行,并且不和别人的程序打交道,那么你完全可以忽略字节序的存在。但 是,如果你的程序要跟别人的程序产生交互呢?在这里我想说说两种语言。C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而 J***A编写的程序则唯一采用big endian方式来存储数据。试想,如果你用C/C++语言在x86平台下编写的程序跟别人的J***A程序互通时会产生什么结果?就拿上面的 0x12345678来说,你的程序传递给别人的一个数据,将指向0x12345678的指针传给了J***A程序,由于J***A采取big endian方式存储数据,很自然的它会将你的数据翻译为0x78563412。什么?竟然变成另外一个数字了?是的,就是这种后果。因此,在你的C程序 传给J***A程序之前有必要进行字节序的转换工作。
无独有偶,所有网络协议也都是采用big endian的方式来传输数据的。所以有时我们也会把big endian方式称之为网络字节序。当两台采用不同字节序的主机通信时,在发送数据之前都必须经过字节序的转换成为网络字节序后再进行传输。ANSI C中提供了下面四个转换字节序的宏。
·BE和LE一文的补完
我在8月9号的《Big Endian和Little Endian》一文中谈了字节序的问题,原文见上面的超级链接。可是有朋友仍然会问,CPU存储一个字节的数据时其字节内的8个比特之间的顺序是否也有 big endian和little endian之分?或者说是否有比特序的不同?
实际上,这个比特序是同样存在的。下面以数字0xB4(10110100)用图加以说明。
Big Endian
msb lsb
---------------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Little Endian
lsb msb
---------------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
实际上,由于CPU存储数据操作的最小单位是一个字节,其内部的比特序是什么样对我们的程序来说是一个黑盒子。也就是说,你给我一个指向0xB4这个数的 指针,对于big endian方式的CPU来说,它是从左往右依次读取这个数的8个比特;而对于little endian方式的CPU来说,则正好相反,是从右往左依次读取这个数的8个比特。而我们的程序通过这个指针访问后得到的数就是0xB4,字节内部的比特 序对于程序来说是不可见的,其实这点对于单机上的字节序来说也是一样的。
那可能有人又会问,如果是网络传输呢?会不会出问题?是不是也要通过什么函数转换一下比特序?嗯,这个问题提得很好。假设little endian方式的CPU要传给big endian方式CPU一个字节的话,其本身在传输之前会在本地就读出这个8比特的数,然后再按照网络字节序的顺序来传输这8个比特,这样的话到了接收端 不会出现任何问题。而假如要传输一个32比特的数的话,由于这个数在littel endian方存储时占了4个字节,而网络传输是以字节为单位进行的,little endian方的CPU读出第一个字节后发送,实际上这个字节是原数的LSB,到了接收方反倒成了MSB从而发生混乱。
【用函数判断系统是Big Endian还是Little Endian】
bool IsBig_Endian()
//如果字节序为big-endian,返回true;
//反之为 little-endian,返回false
{
unsigned short test = 0x1122;
if(*( (unsigned char*) &test ) == 0x11)
return TRUE;
else
return FALSE;
=======================================================================
字节序问题--大端法小端法
一、字节序定义
字节序,顾名思义字节的顺序,再多说两句就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。
其实大部分人在实际的开发中都很少会直接和字节序打交道。唯有在跨平台以及网络程序中字节序才是一个应该被考虑的问题。
在所有的介绍字节序的文章中都会提到字节序分为两类:Big-Endian和Little-Endian。引用标准的Big-Endian和Little-Endian的定义如下:
a) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
c) 网络字节序:4个字节的32 bit值以下面的次序传输:首先是0~7bit,其次8~15bit,然后16~23bit,最后是24~31bit。这种传输次序称作大端字节序。由于 TCP/IP首部中所有的二进制整数在网络中传输时都要求以这种次序,因此它又称作网络字节序。比如,以太网头部中2字节的“以太网帧类型”,表示后面数据的类型。对于ARP请求或应答的以太网帧类型 来说,在网络传输时,发送的顺序是0x08,0x06。在内存中的映象如下图所示:
栈底 (高地址)
---------------
0x06 -- 低位
0x08 -- 高位
---------------
栈顶 (低地址)
该字段的值为0x0806。按照大端方式存放在内存中。
二、高/低地址与高低字节
首先我们要知道我们C程序映像中内存的空间布局情况:在《C专家编程》中或者《Unix环境高级编程》中有关于内存空间布局情况的说明,大致如下图:
----------------------- 最高内存地址 0xffffffff
| 栈底
.
. 栈
.
栈顶
-----------------------
|
|
\|/
NULL (空洞)
/|\
|
|
-----------------------
堆
-----------------------
未初始化的数据
----------------(统称数据段)
初始化的数据
-----------------------
正文段(代码段)
----------------------- 最低内存地址 0x00000000
以上图为例如果我们在栈上分配一个unsigned char buf[4],那么这个数组变量在栈上是如何布局的呢[注1]?看下图:
栈底 (高地址)
----------
buf[3]
buf[2]
buf[1]
buf[0]
----------
栈顶 (低地址)
现在我们弄清了高低地址,接着来弄清高/低字节,如果我们有一个32位无符号整型0x12345678(呵呵,恰好是把上面的那4个字节buf看成 一个整型),那么高位是什么,低位又是什么呢?其实很简单。在十进制中我们都说靠左边的是高位,靠右边的是低位,在其他进制也是如此。就拿 0x12345678来说,从高位到低位的字节依次是0x12、0x34、0x56和0x78。
高低地址和高低字节都弄清了。我们再来回顾一下Big-Endian和Little-Endian的定义,并用图示说明两种字节序:
以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:
Big-Endian: 低地址存放高位,如下图:
栈底 (高地址)
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
栈顶 (低地址)
Little-Endian: 低地址存放低位,如下图:
栈底 (高地址)
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
---------------
栈顶 (低地址)
在现有的平台上Intel的X86采用的是Little-Endian,而像Sun的SPARC采用的就是Big-Endian。
三、例子
嵌入式系统开发者应该对Little-endian和Big-endian模式非常了解。采用Little-endian模式的CPU对操作数的存放方式是从低字节到高字节,而Big-endian模式对操作数的存放方式是从高字节到低字节。
例如,16bit宽的数0x1234在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址 存放内容
0x4001 0x12
0x4000 0x34
而在Big-endian模式CPU内存中的存放方式则为:
内存地址 存放内容
0x4001 0x34
0x4000 0x12
32bit宽的数0x12345678在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址 存放内容
0x4003 0x12
0x4002 0x34
0x4001 0x56
0x4000 0x78
而在Big-endian模式CPU内存中的存放方式则为:
内存地址 存放内容
0x4003 0x78
0x4002 0x56
0x4001 0x34
0x4000 0x12
三、例子
测试平台 : Sun SPARC Solaris 9 和 Intel X86 Solaris 9
我们的例子是这样的:在使用不同字节序的平台上使用相同的程序读取同一个二进制文件的内容。
生成二进制文件的程序如下 :
/* gen_binary.c */
int main() {
FILE *fp = NULL;
int value = 0x12345678;
int rv = 0;
fp = fopen("temp.dat", "wb");
if (fp == NULL) {
printf("fopen error\n");
return -1;
}
rv = fwrite(&value, sizeof(value), 1, fp);
if (rv != 1) {
printf("fwrite error\n");
return -1;
}
fclose(fp);
return 0;
}
读取二进制文件的程序如下:
int main() {
int value = 0;
FILE *fp = NULL;
int rv = 0;
unsigned char buf[4];
fp = fopen("temp.dat", "rb");
if (fp == NULL) {
printf("fopen error\n");
return -1;
}
rv = fread(buf, sizeof(unsigned char), 4, fp);
if (rv != 4) {
printf("fread error\n");
return -1;
}
memcpy(&value, buf, 4); // or value = *((int*)buf);
printf("the value is %x\n", value);
fclose(fp);
return 0;
}
测试过程:
(1) 在 SPARC 平台下生成 temp.dat 文件
在 SPARC 平台下读取 temp.dat 文件的结果:
the value is 12345678
在 X86 平台下读取 temp.dat 文件的结果:
the value is 78563412
(1) 在 X86 平台下生成 temp.dat 文件
在 SPARC 平台下读取 temp.dat 文件的结果:
the value is 78563412
在 X86 平台下读取 temp.dat 文件的结果:
the value is 12345678
[ 注 1]
buf[4] 在栈的布局我也是通过例子程序得到的:
int main() {
unsigned char buf[4];
printf("the buf[0] addr is %x\n", buf);
printf("the buf[1] addr is %x\n", &buf[1]);
return 0;
}
output:
SPARC 平台:
the buf[0] addr is ffbff788
the buf[1] addr is ffbff789
X86 平台:
the buf[0] addr is 8047ae4
the buf[1] addr is 8047ae5
两个平台都是 buf[x] 所在地址高于 buf[y] (x > y) 。
如何判断系统是Big Endian还是Little Endian?
在/usr /include/中(包括子目录)查找字符串BYTE_ORDER(或_BYTE_ORDER, __BYTE_ORDER),确定其值。这个值一般在endian.h或machine/endian.h文件中可以找到,有时在feature.h中, 不同的操作系统可能有所不同。一般来说,Little Endian系统BYTE_ORDER(或_BYTE_ORDER,__BYTE_ORDER)为1234,Big Endian系统为4321。大部分用户的操作系统(如windows, FreeBsd,Linux)是Little Endian的。少部分,如MAC OS ,是Big Endian 的。本质上说,Little Endian还是Big Endian与操作系统和芯片类型都有关系。
Processor OS Order
x86 (Intel, AMD, … ) All little-endian
DEC Alpha All little-endian
HP-PA NT little-endian
HP-PA UNIX big-endian
SUN SPARC All? big-endian
MIPS NT little-endian
MIPS UNIX big-endian
PowerPC NT little-endian
PowerPC non-NT big-endian
RS/6000 UNIX big-endian
Motorola m68k All big-endian